Points de contrôle
Create Namespaces
/ 10
Access Control in Namespaces
/ 25
Resource Quotas
/ 25
Monitoring GKE and GKE Usage Metering
/ 40
Gérer un cluster GKE mutualisé avec des espaces de noms
GSP766

Présentation
Lorsque vous envisagez d'utiliser des solutions d'optimisation des coûts pour une infrastructure Google Cloud basée sur des clusters Google Kubernetes Engine (GKE), il est important de vous assurer que vous utilisez efficacement les ressources qui vous sont facturées. Une erreur courante consiste à attribuer les utilisateurs ou les équipes aux clusters selon un ratio de 1:1, entraînant ainsi une prolifération de clusters.
Un cluster mutualisé permet à plusieurs utilisateurs ou équipes de partager un cluster pour leurs charges de travail tout en assurant l'isolation et le partage équitable des ressources. Pour ce faire, vous devez créer des espaces de noms. Les espaces de noms permettent la coexistence de plusieurs clusters virtuels sur un même cluster physique.
Dans cet atelier, vous allez apprendre à configurer un cluster mutualisé en utilisant plusieurs espaces de noms pour optimiser l'utilisation des ressources et, par la même occasion, les coûts.
Objectifs de l'atelier
-
Créer plusieurs espaces de noms dans un cluster GKE
-
Configurer le contrôle des accès basé sur les rôles pour les espaces de noms
-
Configurer des quotas de ressources Kubernetes pour le partage équitable des ressources entre plusieurs espaces de noms
-
Afficher et configurer les tableaux de bord de surveillance pour vérifier l'utilisation des ressources par espace de noms
-
Générer un rapport de mesure GKE dans Data Studio pour obtenir des métriques précises sur l'utilisation des ressources par espace de noms
Prérequis
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Démarrage
Lorsque vous appuyez sur le bouton Start Lab (Démarrer l'atelier), un message Provisioning Lab Resources (Provisionnement des ressources de l'atelier…) s'affiche en bleu avec une estimation du temps restant. Cela crée et configure l'environnement que vous utiliserez pour tester la gestion d'un cluster mutualisé. Dans un délai de cinq minutes environ, un cluster est créé, les ensembles de données BigQuery sont copiés, et les comptes de service qui représentent les équipes sont générés.
À l'issue de ce processus, le message ne s'affichera plus.
Veuillez patienter jusqu'à la fin du processus de démarrage et la suppression du message pour commencer l'atelier.
Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Télécharger les fichiers requis
Dans cet atelier, certaines étapes utilisent des fichiers YAML pour configurer votre cluster Kubernetes. Dans votre environnement Cloud Shell, téléchargez ces fichiers à partir d'un bucket Cloud Storage :
gsutil -m cp -r gs://spls/gsp766/gke-qwiklab ~
Passez de votre répertoire de travail actuel au répertoire gke-qwiklab :
cd ~/gke-qwiklab
Afficher et créer des espaces de noms
Exécutez la commande suivante pour définir une zone de calcul par défaut et authentifier le cluster mutualisé fourni :
gcloud config set compute/zone us-central1-a && gcloud container clusters get-credentials multi-tenant-cluster
Espaces de noms par défaut
Par défaut, les clusters Kubernetes disposent de quatre espaces de noms système. Vous pouvez obtenir la liste complète des espaces de noms du cluster actuel grâce à cette commande :
kubectl get namespace
Le résultat doit être semblable à ceci :
NAME STATUS AGE
default Active 5m
kube-node-lease Active 5m
kube-public Active 5m
kube-system Active 5m
- default : espace de noms par défaut utilisé lorsqu'aucun autre espace de noms n'est spécifié
- kube-node-lease : gère les objets de bail associés aux pulsations de chaque nœud du cluster
- kube-public : à utiliser pour les ressources qui doivent éventuellement être visibles ou lisibles par tous les utilisateurs dans l'ensemble du cluster
- kube-system : utilisé pour les composants créés par le système Kubernetes
Tous n'appartiennent pas à un espace de noms. Par exemple, les nœuds, les volumes persistants et les espaces de noms eux-mêmes n'appartiennent à aucun espace de noms. Pour obtenir la liste complète des ressources en espace de noms, procédez comme suit :
kubectl api-resources --namespaced=true
Une fois créées, les ressources en espace de noms doivent être associées à un espace de noms. Pour ce faire, vous pouvez inclure l'option --namespace ou indiquer un espace de noms dans le champ de métadonnées du fichier YAML. L'espace de noms peut également être spécifié avec n'importe quelle sous-commande kubectl get pour afficher les ressources d'un espace de noms. Exemple :
kubectl get services --namespace=kube-system
Tous les services de l'espace de noms kube-system sont ainsi renvoyés.
Créer des espaces de noms
Créez deux espaces de noms, pour l'équipe A (team-a) et l'équipe B (team-b) :
kubectl create namespace team-a && \
kubectl create namespace team-b
Le résultat de la commande kubectl get namespace doit maintenant inclure vos deux nouveaux espaces de noms :
NAME STATUS AGE
default Active 5m
kube-node-lease Active 5m
kube-public Active 5m
kube-system Active 5m
team-a Active 88s
team-b Active 88s
En spécifiant le tag --namespace, vous pouvez créer des ressources de cluster dans l'espace de noms fourni. Les noms des ressources telles que les déploiements ou les pods doivent être uniques dans leurs espaces de noms respectifs.
Par exemple, exécutez la commande suivante pour déployer un pod dans les espaces de noms team-a et team-b avec le même nom :
kubectl run app-server --image=centos --namespace=team-a -- sleep infinity && \
kubectl run app-server --image=centos --namespace=team-b -- sleep infinity
Utilisez la commande kubectl get pods -A pour détecter deux pods nommés app-server, un pour chaque espace de noms d'équipe :
kubectl get pods -A
(Résultat)
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system event-exporter-gke-8489df9489-k2blq 2/2 Running 0 3m41s
kube-system fluentd-gke-fmt4v 2/2 Running 0 113s
kube-system fluentd-gke-n9dvn 2/2 Running 0 79s
kube-system fluentd-gke-scaler-cd4d654d7-xj78p 1/1 Running 0 3m37s
kube-system gke-metrics-agent-4jvn8 1/1 Running 0 3m33s
kube-system gke-metrics-agent-b4vvw 1/1 Running 0 3m27s
kube-system kube-dns-7c976ddbdb-gtrct 4/4 Running 0 3m41s
kube-system kube-dns-7c976ddbdb-k9bgk 4/4 Running 0 3m
kube-system kube-dns-autoscaler-645f7d66cf-jwqh5 1/1 Running 0 3m36s
kube-system kube-proxy-gke-new-cluster-default-pool-eb9986d5-tpql 1/1 Running 0 3m26s
kube-system kube-proxy-gke-new-cluster-default-pool-eb9986d5-znm6 1/1 Running 0 3m33s
kube-system l7-default-backend-678889f899-xvt5t 1/1 Running 0 3m41s
kube-system metrics-server-v0.3.6-64655c969-jtl57 2/2 Running 0 3m
kube-system prometheus-to-sd-d6dpf 1/1 Running 0 3m27s
kube-system prometheus-to-sd-rfdlv 1/1 Running 0 3m33s
kube-system stackdriver-metadata-agent-cluster-level-79f9ddf6d6-7ck2w 2/2 Running 0 2m56s
team-a app-server 1/1 Running 0 33s
team-b app-server 1/1 Running 0 33s
Cliquez sur Check my progress (Vérifier ma progression) pour confirmer que vous avez correctement effectué la tâche ci-dessus.
Utilisez la commande kubectl describe pour afficher des informations supplémentaires sur chaque pod créé, en spécifiant l'espace de noms avec le tag "--namespace" :
kubectl describe pod app-server --namespace=team-a
Pour travailler exclusivement avec des ressources dans un espace de noms, vous pouvez le définir une fois pour toutes dans le contexte kubectl au lieu d'utiliser l'option --namespace pour chaque commande :
kubectl config set-context --current --namespace=team-a
Ensuite, toutes les commandes suivantes seront exécutées dans l'espace de noms indiqué sans spécifier l'option --namespace :
kubectl describe pod app-server
Dans la section suivante, vous allez configurer le contrôle des accès basé sur les rôles pour vos espaces de noms, afin de faciliter l'organisation du cluster.
Contrôle des accès dans les espaces de noms
Le provisionnement des accès aux ressources en espace de noms dans un cluster repose sur l'attribution de rôles IAM, associés au contrôle des accès basé sur les rôles (RBAC) intégré à Kubernetes. Un rôle IAM offre à un compte un accès initial au projet, tandis que les autorisations RBAC octroient un accès précis aux ressources associées en espace de noms d'un cluster (pods, déploiements, services, etc.).
Rôles IAM
Lors de la gestion du contrôle des accès pour Kubernetes, Identity and Access Management (IAM) permet de gérer l'accès et les autorisations au niveau de l'organisation et du projet.
Dans IAM, plusieurs rôles peuvent être attribués aux utilisateurs et aux comptes de service pour régir leur niveau d'accès avec GKE. Les autorisations RBAC précises utilisent l'accès déjà fourni par IAM et ne peuvent restreindre l'accès accordé par celui-ci. Par conséquent, pour les clusters en espaces de noms mutualisés, le rôle IAM attribué doit accorder un accès minimal.
Voici un tableau des rôles IAM de GKE courants que vous pouvez attribuer :
| Rôle | Description |
|---|---|
Administrateur de Kubernetes Engine |
Permet la gestion complète des clusters et de leurs objets API Kubernetes. Un utilisateur doté de ce rôle peut créer, modifier et supprimer n'importe quelle ressource dans n'importe quel cluster et les espaces de noms correspondants. |
Développeur sur Kubernetes Engine |
Fournit un accès aux objets de l'API Kubernetes dans les clusters. Un utilisateur doté de ce rôle peut créer, modifier et supprimer des ressources dans n'importe quel cluster et les espaces de noms correspondants. |
Administrateur de cluster Kubernetes Engine |
Permet la gestion des clusters. Un utilisateur doté de ce rôle n'est pas autorisé à créer ou modifier directement des ressources dans un cluster ni dans les espaces de noms correspondants, mais il peut créer, modifier et supprimer des clusters. |
Lecteur Kubernetes Engine |
Fournit un accès en lecture seule aux ressources GKE. Un utilisateur doté de ce rôle dispose d'un accès en lecture seule aux espaces de noms et à leurs ressources. |
Lecteur de cluster Kubernetes Engine |
Permet d'accéder aux clusters GKE et de les répertorier. Il s'agit du rôle minimal requis pour toute personne ayant besoin d'accéder aux ressources dans les espaces de noms d'un cluster. |
Alors que la plupart de ces rôles accordent un accès trop étendu pour permettre une restriction RBAC, le rôle IAM Lecteur de cluster Kubernetes Engine accorde aux utilisateurs suffisamment d'autorisations pour accéder au cluster et aux ressources en espace de noms.
Dans cet atelier, votre projet dispose d'un compte de service représentant un développeur qui utilisera l'espace de noms team-a. Attribuez au compte le rôle Lecteur de cluster Kubernetes Engine en exécutant la commande suivante :
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member=serviceAccount:team-a-dev@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com \
--role=roles/container.clusterViewer
Kubernetes RBAC
Dans un cluster, l'accès à n'importe quel type de ressource (pod, service, déploiement, etc.) est défini par un rôle ou un rôle de cluster. Seuls les rôles peuvent être associés à un espace de noms. Un rôle indique les ressources et l'action autorisées pour chaque ressource, tandis qu'une liaison de rôle indique les comptes ou les groupes d'utilisateurs auxquels attribuer cet accès.
Pour créer un rôle dans l'espace de noms actuel, spécifiez le type de ressource ainsi que les verbes indiquant le type d'action qui sera autorisé. Des rôles avec des règles uniques peuvent être créés à l'aide de la commande kubectl create :
kubectl create role pod-reader \
--resource=pods --verb=watch --verb=get --verb=list
Des rôles comportant plusieurs règles peuvent être créés à l'aide d'un fichier YAML. Un fichier d'exemple est fourni dans les fichiers que vous avez téléchargés précédemment dans cet atelier.
Inspectez le fichier YAML :
cat developer-role.yaml
Exemple de résultat :
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: team-a
name: developer
rules:
- apiGroups: [""]
resources: ["pods", "services", "serviceaccounts"]
verbs: ["update", "create", "delete", "get", "watch", "list"]
- apiGroups:["apps"]
resources: ["deployments"]
verbs: ["update", "create", "delete", "get", "watch", "list"]
Appliquez le rôle ci-dessus :
kubectl create -f developer-role.yaml
Créez une liaison de rôle entre le compte de service team-a-developers et le rôle de développeur :
kubectl create rolebinding team-a-developers \
--role=developer --user=team-a-dev@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Tester la liaison de rôle
Téléchargez les clés du compte de service qui permettent de l'emprunter :
gcloud iam service-accounts keys create /tmp/key.json --iam-account team-a-dev@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Cliquez sur Check my progress (Vérifier ma progression) pour confirmer que vous avez correctement effectué la tâche ci-dessus.
Dans Cloud Shell, cliquez sur + pour ouvrir un nouvel onglet dans votre terminal. Exécutez la commande suivante pour activer le compte de service : Vous pourrez ainsi exécuter les commandes en tant que compte :
gcloud auth activate-service-account --key-file=/tmp/key.json
Récupérez les identifiants de votre cluster en tant que compte de service :
gcloud container clusters get-credentials multi-tenant-cluster --zone us-central1-a --project ${GOOGLE_CLOUD_PROJECT}
Vous constaterez qu'en tant que team-a-dev, vous pouvez répertorier les pods dans l'espace de noms team-a :
kubectl get pods --namespace=team-a
Résultat :
NAME READY STATUS RESTARTS AGE
app-server 1/1 Running 0 6d
Toutefois, l'affichage de la liste des pods dans l'espace de noms team-b est limité :
kubectl get pods --namespace=team-b
Résultat :
Error from server (Forbidden): pods is forbidden: User "team-a-dev@a-gke-project.iam.gserviceaccount.com" cannot list resource "pods" in API group "" in the namespace "team-b": requires one of ["container.pods.list"] permission(s).
Revenez au premier onglet Cloud Shell ou ouvrez-en un nouveau. Renouvelez les identifiants du cluster et réinitialisez votre contexte sur l'espace de noms team-a :
gcloud container clusters get-credentials multi-tenant-cluster --zone us-central1-a --project ${GOOGLE_CLOUD_PROJECT}
Quotas de ressources
Lorsqu'un cluster est partagé selon une configuration mutualisée, il est important de s'assurer que les utilisateurs ne peuvent pas accaparer les ressources de façon inéquitable. Un objet de quota de ressources (ResourceQuota) définit des contraintes qui limitent la consommation des ressources dans un espace de noms. Un quota de ressources peut spécifier une limite pour le nombre d'objets (pods, services, ensembles avec état, etc.), la somme totale des ressources de stockage (revendications de volume persistant, stockage éphémère, classes de stockage) ou la somme totale des ressources de calcul. (processeur et mémoire).
Par exemple, la commande suivante définit une limite sur le nombre de pods autorisés dans l'espace de noms team-a sur 3, et le nombre d'équilibreurs de charge sur 1 :
kubectl create quota test-quota \
--hard=count/pods=2,count/services.loadbalancers=1 --namespace=team-a
Créez un deuxième pod dans l'espace de noms team-a :
kubectl run app-server-2 --image=centos --namespace=team-a -- sleep infinity
Essayez à présent de créer un troisième pod :
kubectl run app-server-3 --image=centos --namespace=team-a -- sleep infinity
Vous devriez recevoir l'erreur suivante :
Error from server (Forbidden): pods "app-server-3" is forbidden: exceeded quota: test-quota, requested: count/pods=1, used: count/pods=2, limited: count/pods=2
Vous pouvez vérifier les détails de votre quota de ressources à l'aide de la commande kubectl describe :
kubectl describe quota test-quota --namespace=team-a
Résultat :
Name: test-quota
Namespace: team-a
Resource Used Hard
-------- ---- ----
count/pods 2 2
count/services.loadbalancers 0 1
Cette liste indique les ressources restreintes par le quota de ressources, la limite stricte configurée et la quantité actuellement utilisée.
Mettez à jour test-quota pour appliquer une limite de six pods, en exécutant la commande suivante :
export KUBE_EDITOR="nano"
kubectl edit quota test-quota --namespace=team-a
Vous pourrez modifier un fichier YAML que kubectl utilisera pour mettre à jour le quota. Le quota inconditionnel correspond à la valeur count/pods sous spec.
Définissez la valeur count/pods sur 6 sous "spec" :
apiVersion: v1
kind: ResourceQuota
metadata:
creationTimestamp: "2020-10-21T14:12:07Z"
name: test-quota
namespace: team-a
resourceVersion: "5325601"
selfLink: /api/v1/namespaces/team-a/resourcequotas/test-quota
uid: a4766300-29c4-4433-ba24-ad10ebda3e9c
spec:
hard:
count/pods: "6"
count/services.loadbalancers: "1"
status:
hard:
count/pods: "5"
count/services.loadbalancers: "1"
used:
count/pods: "2"
Appuyez sur Ctrl+X, puis sur Y pour enregistrer les modifications et quitter la page.
Le quota mis à jour doit maintenant apparaître dans le résultat :
kubectl describe quota test-quota --namespace=team-a
(Résultat)
Name: test-quota
Namespace: team-a
Resource Used Hard
-------- ---- ----
count/pods 2 6
count/services.loadbalancers 0 1
Quotas de ressources processeur et mémoire
Lorsque vous définissez des quotas pour le processeur et la mémoire, vous pouvez indiquer un quota pour la somme des demandes (une valeur qu'un conteneur est assuré d'obtenir) ou la somme des limites (une valeur qu'un conteneur ne sera jamais autorisé à dépasser).
Dans cet atelier, votre cluster dispose de quatre machines e2-medium, avec chacune un cœur et 3,75 Go de mémoire. Un exemple de fichier YAML de quota de ressources vous a été fourni pour votre cluster :
cpu-mem-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-mem-quota
namespace: team-a
spec:
hard:
limits.cpu: "4"
limits.memory: "12Gi"
requests.cpu: "2"
requests.memory: "8Gi"
Appliquez la configuration du fichier :
kubectl create -f cpu-mem-quota.yaml
Une fois ce quota en place, la somme des demandes de ressources mémoire et processeur de tous les pods est limitée à 2 processeurs et 8 Gio, et leurs limites respectives à 4 processeurs et 12 Gio.
Pour illustrer le quota de processeurs et de mémoire, créez un nouveau pod à l'aide de cpu-mem-demo-pod.yaml :
cpu-mem-demo-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: cpu-mem-demo
namespace: team-a
spec:
containers:
- name: cpu-mem-demo-ctr
image: nginx
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "400m"
memory: "512Mi"
Appliquez la configuration du fichier :
kubectl create -f cpu-mem-demo-pod.yaml --namespace=team-a
Une fois ce pod créé, exécutez la commande suivante pour que les demandes et limites de processeur et de mémoire soient reflétées dans le quota :
kubectl describe quota cpu-mem-quota --namespace=team-a
(Résultat)
Name: cpu-mem-quota
Namespace: team-a
Resource Used Hard
-------- ---- ----
limits.cpu 400m 4
limits.memory 512Mi 12Gi
requests.cpu 100m 2
requests.memory 128Mi 8Gi
Cliquez sur Check my progress (Vérifier ma progression) pour confirmer que vous avez correctement effectué la tâche ci-dessus.
Surveillance de GKE et mesure de l'utilisation de GKE
Pour la plupart des clusters mutualisés, il est probable que les charges de travail et les ressources nécessaires pour chacun des locataires évoluent et que les quotas de ressources aient besoin d'être modifiés. Grâce à Monitoring, vous pouvez obtenir une vue générale des ressources utilisées par chaque espace de noms.
La mesure de l'utilisation de GKE vous permet d'obtenir une vue plus précise de cette utilisation des ressources, et donc de vous faire une meilleure idée des coûts associés à chaque locataire.
Tableau de bord Monitoring
Dans Cloud Console, cliquez sur le menu de navigation en haut à gauche de la page, puis sur Operations > Surveillance (Opérations > Surveillance) dans ce menu.
Patientez une minute, le temps que l'espace de travail soit créé pour votre projet. Une fois sur la page "Overview" (Vue d'ensemble), sélectionnez Dashboards (Tableaux de bord) dans le menu de gauche :
Sélectionnez GKE sur la page Dashboards Overview (Aperçu des tableaux de bord). Le tableau de bord GKE présente un ensemble de tables qui détaillent l'utilisation du processeur, de la mémoire et du disque, en fonction de plusieurs ressources.
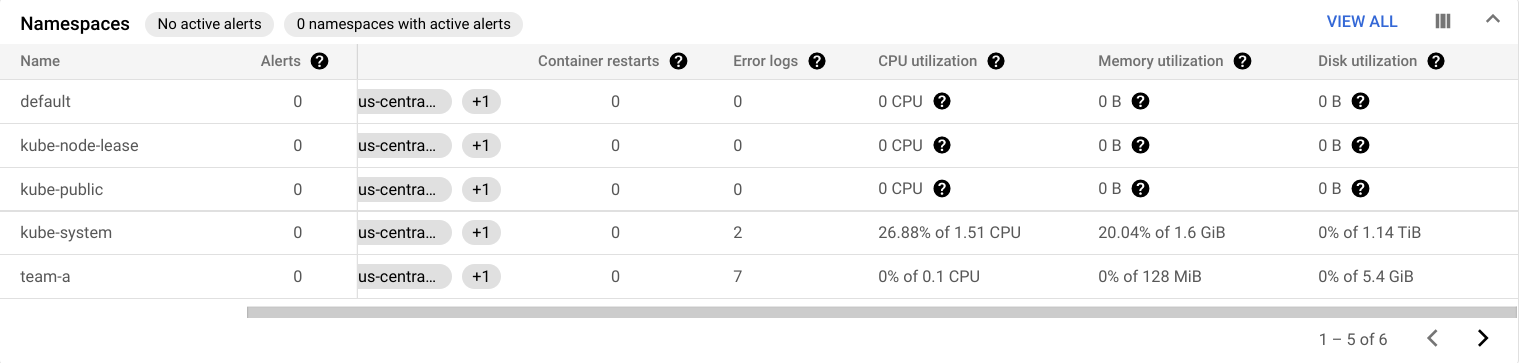
Par exemple, la table Namespaces indique l'utilisation de chacun des espaces de noms de vos clusters :
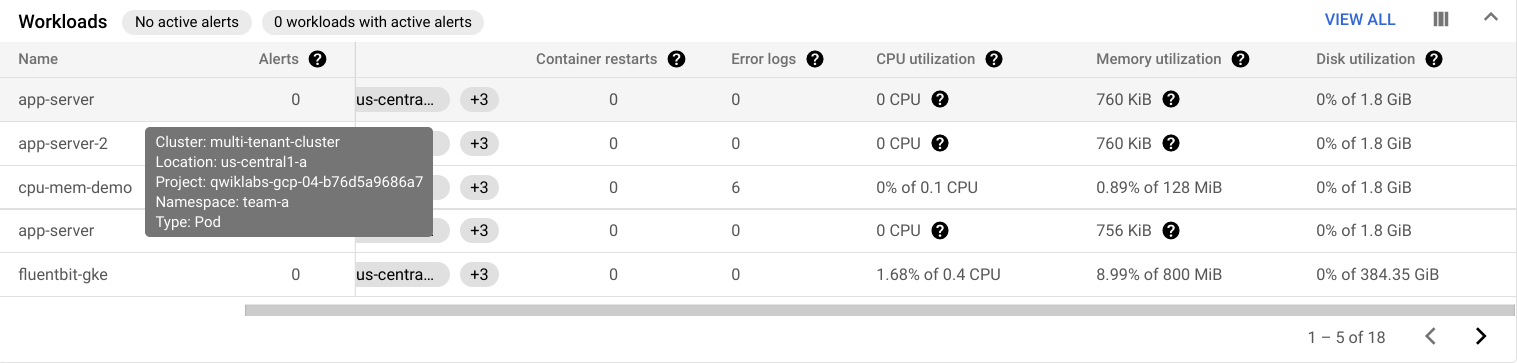
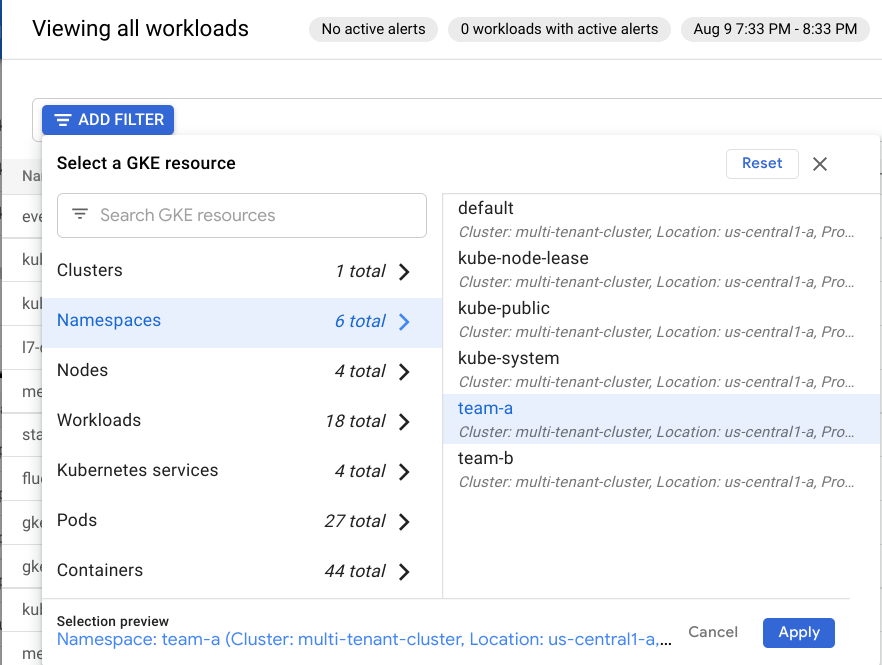
Vous pouvez également consulter les données d'utilisation des charges de travail exécutées sur votre cluster dans la table Workloads. Cliquez sur View All (Tout afficher), puis dans la zone Filter By Resource (Filtrer par ressource), sélectionnez Namespaces (espaces de noms) > team-a. Cliquez ensuite sur Apply (Appliquer).
Cela filtrera les charges de travail de façon à n'inclure que celles qui s'exécutent sur l'espace de noms team-a :
Explorateur de métriques
Dans le volet de gauche, sélectionnez Metrics Explorer (Explorateur de métriques).
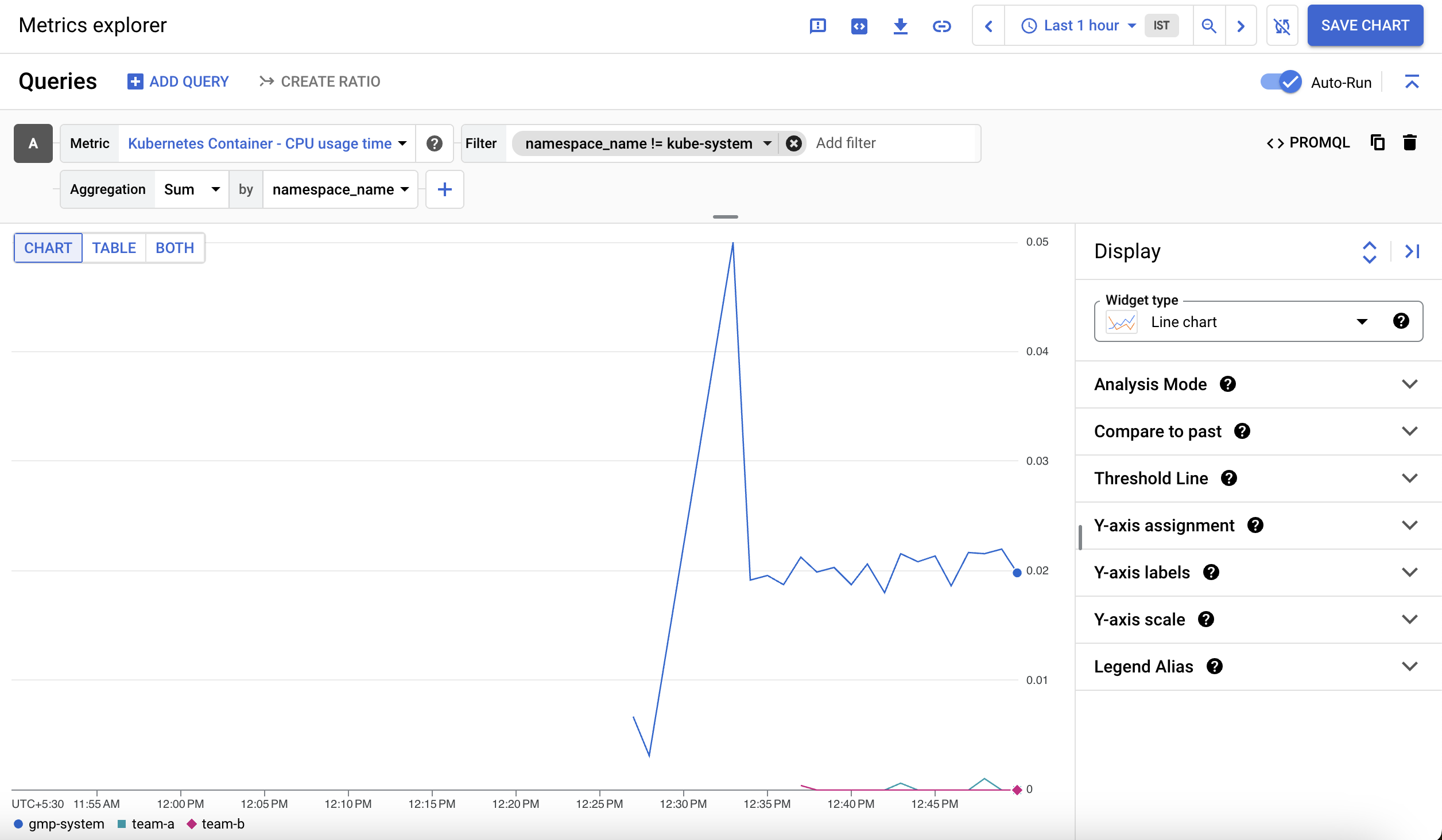
Dans la zone intitulée Find resource type and metric (Rechercher le type de ressource et la métrique), saisissez Kubernetes Container (Conteneur Kubernetes) comme type de ressource et sélectionnez CPU usage time (Temps d'utilisation du processeur).
Pour exclure l'espace de noms kube-system, cliquez sur Add a filter (Ajouter un filtre) dans la section de filtre et sélectionnez namespace_name. Sélectionnez l'opérateur != et la valeur kube-system.
Ensuite, dans le champ Group by (Grouper par), saisissez namespace_name. Vous verrez un graphique illustrant le temps d'utilisation du processeur du conteneur par espace de noms :
Mesure de l'utilisation de GKE
La mesure de l'utilisation de GKE vous permet d'exporter l'utilisation et la consommation des ressources du cluster GKE vers un ensemble de données BigQuery où vous pouvez les visualiser à l'aide de Data Studio. Elle permet d'obtenir une vue plus précise de l'utilisation des ressources. La mesure de l'utilisation vous permet en outre de prendre des décisions plus éclairées concernant les quotas de ressources et la configuration efficace des clusters.
Les deux ensembles de données suivants ont été ajoutés à votre projet :
cluster_dataset : ensemble de données créé manuellement avant d'activer la mesure de l'utilisation de GKE sur le cluster. Cet ensemble de données contient deux tables générées par GKE (gke_cluster_resource_consumption et gke_cluster_resource_usage). Il est mis à jour en continu à l'aide des métriques d'utilisation des clusters.
billing_dataset : ensemble de données créé manuellement avant l'activation de l'exportation vers BigQuery pour la facturation. Cet ensemble de données contient une table (gcp_billing_export_v1_xxxx). Il est mis à jour quotidiennement avec les coûts journaliers d'un projet.
Exécutez la commande suivante pour activer la mesure de l'utilisation de GKE sur le cluster et spécifier l'ensemble de données cluster_dataset :
gcloud container clusters \
update multi-tenant-cluster --zone us-central1-a \
--resource-usage-bigquery-dataset cluster_dataset
Créer la table de répartition des coûts pour GKE
Une table de répartition des coûts peut être générée à partir des tables de facturation et d'utilisation des ressources de votre projet. Vous pouvez le faire dans l'ensemble de données du cluster à l'aide du fichier usage_metering_query_template.sql. Ce modèle est disponible sur la page de documentation relative à la mesure de l'utilisation du cluster.
Tout d'abord, dans Cloud Shell, définissez des variables d'environnement.
Définissez le chemin d'accès de la table de facturation fournie, l'ensemble de données de mesure de l'utilisation fourni et un nom pour la nouvelle table de répartition des coûts :
export GCP_BILLING_EXPORT_TABLE_FULL_PATH=${GOOGLE_CLOUD_PROJECT}.billing_dataset.gcp_billing_export_v1_xxxx
export USAGE_METERING_DATASET_ID=cluster_dataset
export COST_BREAKDOWN_TABLE_ID=usage_metering_cost_breakdown
Ensuite, spécifiez le chemin d'accès du modèle de requête de mesure de l'utilisation téléchargé au début de cet atelier, un fichier de sortie pour la requête de mesure de l'utilisation qui sera générée, et une date de début pour les données (la première date étant 2020-10-26) :
export USAGE_METERING_QUERY_TEMPLATE=~/gke-qwiklab/usage_metering_query_template.sql
export USAGE_METERING_QUERY=cost_breakdown_query.sql
export USAGE_METERING_START_DATE=2020-10-26
Générez à présent la requête de mesure de l'utilisation à l'aide des variables d'environnement ci-dessous et du modèle de requête :
sed \
-e "s/\${fullGCPBillingExportTableID}/$GCP_BILLING_EXPORT_TABLE_FULL_PATH/" \
-e "s/\${projectID}/$GOOGLE_CLOUD_PROJECT/" \
-e "s/\${datasetID}/$USAGE_METERING_DATASET_ID/" \
-e "s/\${startDate}/$USAGE_METERING_START_DATE/" \
"$USAGE_METERING_QUERY_TEMPLATE" \
> "$USAGE_METERING_QUERY"
Exécutez la commande suivante pour configurer votre table de répartition des coûts à l'aide de la requête exécutée à l'étape précédente :
bq query \
--project_id=$GOOGLE_CLOUD_PROJECT \
--use_legacy_sql=false \
--destination_table=$USAGE_METERING_DATASET_ID.$COST_BREAKDOWN_TABLE_ID \
--schedule='every 24 hours' \
--display_name="GKE Usage Metering Cost Breakdown Scheduled Query" \
--replace=true \
"$(cat $USAGE_METERING_QUERY)"
Le transfert de données doit fournir un lien d'autorisation. Cliquez dessus, connectez-vous avec votre compte étudiant, suivez les instructions et collez à nouveau la commande version_info dans Cloud Shell.
Ensuite, un message indiquant que la configuration du transfert a été créée doit s'afficher.
Créer la source de données dans Data Studio
Cliquez sur le lien ci-dessous pour accéder à la page des sources de données Data Studio :
En haut à gauche, cliquez sur Create > Data Source (Créer > Source de données) pour ajouter une source de données.
La fenêtre Welcome to Data Studio (Bienvenue dans Data Studio) s'affiche.
Cliquez sur Get Started (Commencer).
Cochez la case indiquant que vous avez pris connaissance des conditions, puis cliquez sur Accept (Accepter).
Sélectionnez No, thanks (Non, merci) pour chaque conseil et recommandation, car il s'agit d'un atelier/compte temporaire.
Cliquez sur CONTINUE (Continuer).
La liste des connecteurs Google compatibles avec Data Studio s'affiche. Sélectionnez BigQuery dans la liste.
Cliquez sur le bouton Authorize (Autoriser) pour permettre à Data Studio d'accéder à votre projet BigQuery.
En haut à gauche de la page, renommez votre source de données en remplaçant "Source de données sans titre" par "Utilisation de GKE".
Dans la première colonne, sélectionnez CUSTOM QUERY (Requête personnalisée).
Sélectionnez votre ID de projet dans la colonne des projets.
Saisissez la requête suivante dans la zone de requête personnalisée, en remplaçant [PROJECT-ID] par l'ID de votre projet Qwiklabs :
SELECT * FROM `[PROJECT-ID].cluster_dataset.usage_metering_cost_breakdown`
Cliquez sur CONNECT (Connecter).
Cliquez sur Check my progress (Vérifier ma progression) pour confirmer que vous avez correctement effectué la tâche ci-dessus.
Cliquez ensuite en haut à droite. Maintenant que la source de données a été ajoutée, vous pouvez l'utiliser pour créer un rapport. En haut de la page de votre source de données, cliquez sur Create Report (Créer un rapport).
Lorsque vous créez un rapport à partir d'une source de données, vous êtes invité à ajouter des données à votre rapport. Cliquez sur Add to Report (Ajouter au rapport) :
Créer un rapport Data Studio
Le rapport vous permet de visualiser les métriques d'utilisation de la source de données en fonction de votre table BigQuery.
Vous commencerez par utiliser une table simple :
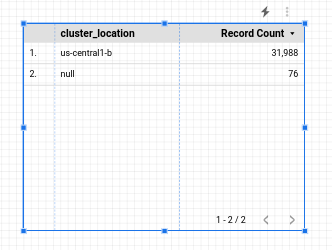
Configurez cette table de façon à afficher une répartition des coûts par espace de noms. Une fois le tableau sélectionné, les données correspondantes s'affichent dans le panneau de droite.
Modifiez les éléments suivants dans ce panneau :
- Dimension associée à la plage de données : usage_start_time
- Dimension : namespace (espace de noms)
- Métrique : cost (coût)
Conservez les valeurs par défaut dans les autres champs.
Pour limiter votre table aux ressources en espace de noms, vous pouvez appliquer un filtre. Dans le panneau des données, cliquez sur "Add a Filter" (Ajouter un filtre) dans la section "Filter" (Filtre). Créez un filtre pour exclure les ressources non allouées à un espace de noms :

Cliquez sur Save (Enregistrer).
Cliquez à nouveau sur Add a Filter (Ajouter un filtre), puis sur Create a Filter (Créer un filtre) pour créer un second filtre permettant de limiter les données aux requêtes :

Cliquez sur Save (Enregistrer) pour appliquer le filtre. La table obtenue doit se présenter comme suit :

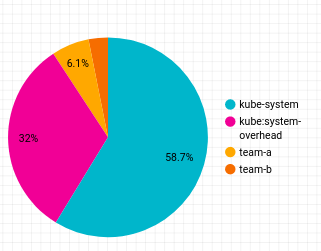
Ajoutez ensuite à votre rapport un graphique à secteurs présentant la répartition des coûts par espace de noms. Cliquez avec le bouton droit sur la table que vous avez créée, puis sélectionnez Duplicate (Dupliquer). Faites glisser l'objet de table dupliquée n'importe où dans votre rapport.
Cliquez ensuite sur l'en-tête du panneau de configuration :
Dans les options affichées, cliquez sur l'icône de graphique à secteurs :

Le graphique à secteurs obtenu ressemblera à ceci :
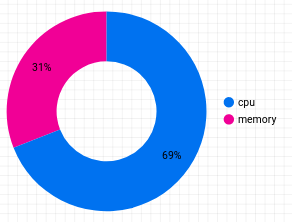
Ajoutez maintenant un graphique en anneau qui indique la répartition des coûts par type de ressource. Dans la barre d'outils située en haut, cliquez sur Add a chart (Ajouter un graphique), puis sélectionnez 
- Dimension associée à la plage de données : usage_start_time
- Dimension : resource_name
- Métrique : coût
Cliquez sur Add a Filter (Ajouter un filtre), puis sélectionnez les deux filtres appliqués au graphique précédent. Le graphique en anneau obtenu se présentera comme suit :
Pour ajouter une répartition par espace de noms, cliquez sur Add a control (Ajouter une commande) dans la barre d'outils supérieure, puis sélectionnez Drop-down list (Liste déroulante). Faites-la glisser à côté du graphique en anneau et configurez-la comme suit :
- Dimension associée à la plage de données : usage_start_time
- Champ de commande : resource_name
- Métrique : None (aucune)
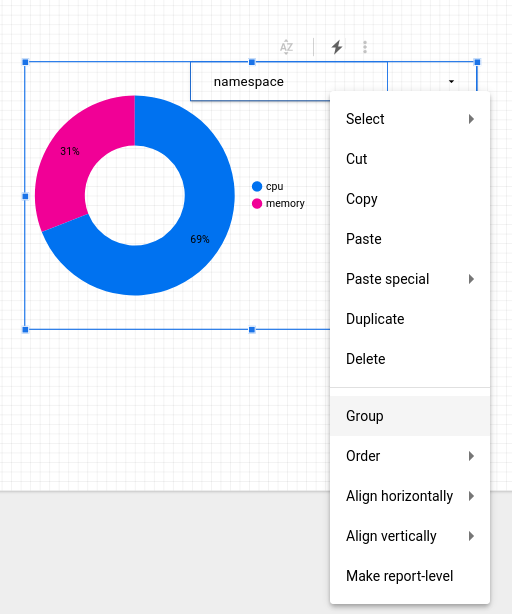
Cliquez sur Add a filter (Ajouter un filtre), puis sélectionnez le filtre namespace (espace de noms) dans la liste.
Pour configurer la commande afin qu'elle n'affecte que le graphique en anneau, sélectionnez l'objet de commande et le graphique à l'aide du curseur de sélection, afin de dessiner un rectangle autour des deux objets. Effectuez un clic droit et sélectionnez "Group" (Groupe) pour les lier à un groupe :
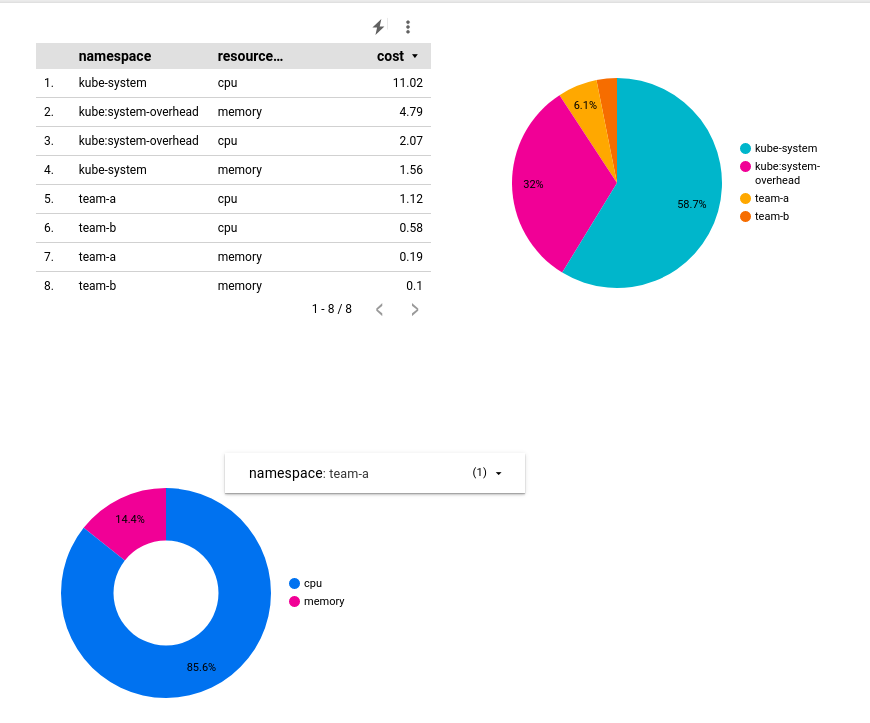
Pour prévisualiser votre rapport, cliquez sur View (Afficher) dans la barre d'outils supérieure. Dans ce mode, vous pouvez régler l'affichage de votre graphique en anneau sur un espace de noms spécifique :
Dans le menu Share (Partager) situé en haut de la page, cliquez sur Download report (Télécharger le rapport) pour télécharger une copie du rapport complet au format PDF :
Félicitations !
Vous pouvez utiliser les espaces de noms afin de configurer des clusters en tant qu'architecture mutualisée, de minimiser les risques de sous-utilisation des ressources et de prolifération de clusters, et d'éviter les coûts supplémentaires. Grâce à la surveillance et à la mesure de l'utilisation de GKE, vous pouvez également visualiser l'utilisation des ressources par espace de noms et prendre des décisions plus éclairées sur les quotas de ressources et la configuration des clusters.

Terminer votre quête
Cet atelier d'auto-formation fait partie de la quête Qwiklabs Optimize Costs for Google Kubernetes Engine.
Une quête est une série d'ateliers associés qui constituent une formation. Si vous terminez cette quête, vous obtiendrez le badge ci-dessus attestant de votre réussite.
Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux.
Inscrivez-vous à cette quête pour obtenir immédiatement les crédits associés à cet atelier si vous l'avez suivi.
Découvrez les autres quêtes Qwiklabs disponibles.
Atelier suivant
Continuez sur votre lancée en suivant l'atelier Optimiser les coûts pour Google Kubernetes Engine, ou consultez ces suggestions :
Étapes suivantes et informations supplémentaires
- Documentation sur l'architecture de cluster mutualisée
- Bonnes pratiques pour l'exécution d'applications Kubernetes à coût maîtrisé sur GKE
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 23 avril 2021
Dernier test de l'atelier : 23 avril 2021
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.