Points de contrôle
Provision testing environment
/ 20
Scale pods with Horizontal Pod Autoscaling
/ 20
Scale size of pods with Vertical Pod Autoscaling
/ 20
Cluster autoscaler
/ 20
Node Auto Provisioning
/ 10
Optimize larger loads
/ 10
Comprendre et combiner les stratégies d'autoscaling de GKE
- GSP768
- Présentation
- Préparation
- Adapter le nombre de pods par autoscaling horizontal
- Adapter la taille des pods par autoscaling vertical
- Résultats du HPA
- Résultats du VPA
- Autoscaler de cluster
- Provisionnement automatique des nœuds
- Tester avec une demande plus importante
- Optimiser les charges importantes
- Félicitations !
GSP768

Présentation
Google Kubernetes Engine propose des solutions horizontales et verticales pour le scaling automatique des pods et de l'infrastructure. Ces outils s'avèrent très utiles pour optimiser les coûts, car ils favorisent une exécution efficace de vos charges de travail et vous assurent de ne payer que pour les ressources que vous utilisez.
Dans cet atelier, vous allez configurer et observer l'autoscaling horizontal et l'autoscaling vertical au niveau des pods, ainsi que l'autoscaler de cluster (solution d'infrastructure horizontale) et le provisionnement automatique des nœuds (solution d'infrastructure verticale) au niveau des nœuds. Dans un premier temps, vous allez utiliser ces outils d'autoscaling pour limiter autant que possible la consommation de ressources et réduire la taille de votre cluster lors des périodes creuses. Vous augmenterez ensuite le volume de demandes envoyées au cluster et observerez comment l'autoscaling maintient la disponibilité.
Objectifs de l'atelier
-
Réduire le nombre d'instances dupliquées pour un déploiement avec l'autoscaler de pods horizontal
-
Réduire la demande de processeur d'un déploiement avec l'autoscaler de pods vertical
-
Diminuer le nombre de nœuds utilisés dans un cluster avec l'autoscaler de cluster
-
Créer automatiquement un pool de nœuds optimisé pour une charge de travail avec le provisionnement automatique des nœuds
-
Tester le comportement de l'autoscaling en cas de pic de demande
-
Surprovisionner le cluster avec les pods de pause
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Provisionner l'environnement de test
Définissez la zone par défaut sur us-central1-a :
gcloud config set compute/zone us-central1-a
Exécutez la commande suivante pour créer un cluster à trois nœuds dans la zone us-central1-a :
gcloud container clusters create scaling-demo --num-nodes=3 --enable-vertical-pod-autoscaling
Pour illustrer l'autoscaling horizontal des pods, cet atelier utilise une image Docker personnalisée basée sur l'image php-apache. Elle définit une page index.php effectuant divers calculs qui sollicitent fortement le processeur. Vous surveillerez un déploiement de cette image.
Créez un fichier manifeste pour le déploiement php-apache :
cat << EOF > php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 3
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
EOF
Appliquez le fichier manifeste ainsi créé à votre cluster :
kubectl apply -f php-apache.yaml
Cliquez sur Check my progress (Vérifier ma progression) pour valider que vous avez correctement effectué la tâche ci-dessus.
Adapter le nombre de pods par autoscaling horizontal
L'autoscaling horizontal des pods modifie la forme de votre charge de travail Kubernetes. Il augmente ou réduit automatiquement le nombre de pods selon les ressources de processeur ou de mémoire consommées par la charge de travail, ou selon des métriques personnalisées provenant de Kubernetes ou des métriques issues de sources extérieures au cluster.
Dans Cloud Shell, exécutez la commande suivante pour inspecter les déploiements de votre cluster :
kubectl get deployment
Vous devriez voir le déploiement php-apache apparaître avec trois pods en cours d'exécution :

Appliquez un autoscaling horizontal au déploiement php-apache :
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
Cliquez sur Check my progress (Vérifier ma progression) pour valider que vous avez correctement effectué la tâche ci-dessus.
Cette commande autoscale configure un autoscaler de pods horizontal (HPA, Horizontal Pod Autoscaler) qui maintiendra entre 1 et 10 le nombre d'instances dupliquées des pods contrôlés par le déploiement php-apache. L'option cpu-percent cible 50 % d'utilisation moyenne du processeur demandé pour l'ensemble des pods. Le HPA ajuste le nombre d'instances dupliquées (via le déploiement) pour maintenir à 50 % l'utilisation moyenne du processeur sur l'ensemble des pods.
Vérifiez l'état actuel du HPA :
kubectl get hpa
Vous devriez voir 0 %/50 % dans la colonne Targets (Cibles).
Cela signifie que les pods de votre déploiement sont actuellement à 0 % de l'utilisation moyenne cible du processeur. Ce comportement est normal, car l'application php-apache ne reçoit aucun trafic pour le moment.
Notez également la valeur indiquée dans la colonne Replicas (Instances dupliquées). Pour l'instant, elle s'élève à 3, mais sera modifiée par l'autoscaler à mesure que le nombre de pods requis évoluera.
En l'occurrence, l'autoscaler va faire évoluer le déploiement à la baisse, jusqu'au nombre minimal de pods indiqué dans la commande autoscale. L'autoscaling de pods horizontal prend entre 5 et 10 minutes et implique d'arrêter des pods ou d'en démarrer de nouveaux selon le sens du scaling.
Passez à l'étape suivante de l'atelier. Vous examinerez les résultats de l'autoscaler plus tard.
Adapter la taille des pods par autoscaling vertical
L'autoscaling de pods vertical vous évite d'avoir à réfléchir aux valeurs à spécifier dans les demandes de processeur et de mémoire. L'autoscaler peut recommander des valeurs pour les demandes et les limites de processeur et de mémoire, ou modifier automatiquement ces valeurs.
Le VPA a déjà été activé sur le cluster scaling-demo. Pour le vérifier, exécutez la commande suivante :
gcloud container clusters describe scaling-demo | grep ^verticalPodAutoscaling -A 1
La sortie doit indiquer enabled: true.
Pour montrer l'action du VPA, vous allez déployer l'application hello-server.
Appliquez le déploiement hello-server à votre cluster :
kubectl create deployment hello-server --image=gcr.io/google-samples/hello-app:1.0
Vérifiez que le déploiement a bien été créé :
kubectl get deployment hello-server
Associez une demande de processeur de 450 millicœurs au déploiement :
kubectl set resources deployment hello-server --requests=cpu=450m
Ensuite, exécutez la commande suivante pour afficher les détails du conteneur des pods hello-server :
kubectl describe pod hello-server | sed -n "/Containers:$/,/Conditions:/p"
Dans la sortie, recherchez Requests (Demandes). Notez que ce pod demande actuellement le processeur de 450 millicœurs précédemment attribué.
Créez maintenant un fichier manifeste pour le VPA :
cat << EOF > hello-vpa.yaml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: hello-server-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: hello-server
updatePolicy:
updateMode: "Off"
EOF
La commande ci-dessus génère le fichier manifeste d'un VPA ciblant le déploiement hello-server avec une règle de mise à jour Off (Désactivée). Vous pouvez appliquer l'une des trois règles de mise à jour suivante au VPA en fonction de l'application :
- Off (Désactivée) : le VPA utilise les données de l'historique pour recommander des mises à jour que vous pouvez appliquer manuellement.
- Initial (Initiale) : les recommandations du VPA s'appliquent une fois à la création des pods, mais ne modifient plus la taille des pods ensuite.
- Auto (Automatique) : des pods sont régulièrement supprimés et recréés en fonction de la taille recommandée.
Appliquez le fichier manifeste à hello-vpa :
kubectl apply -f hello-vpa.yaml
Attendez une minute, puis affichez le VerticalPodAutoscaler :
kubectl describe vpa hello-server-vpa
Recherchez la section "Container Recommandations" (Recommandations pour les conteneurs) à la fin de la sortie. Si vous ne la voyez pas, patientez encore un peu, puis relancez la commande précédente. Vous trouverez dans cette section de nombreux types de recommandations, chacune associée à des valeurs de processeur et de mémoire :
- Lower Bound (Limite inférieure) : limite inférieure à partir de laquelle le VPA déclenche un redimensionnement. Si l'utilisation du pod passe en dessous de cette limite, le VPA supprime le pod et le fait évoluer à la baisse.
- Target (Cible) : valeur utilisée par le VPA pour redimensionner le pod.
- Uncapped Target (Cible non plafonnée) : si vous n'attribuez aucune capacité minimale ou maximale au VPA, cette valeur représentera l'utilisation cible pour le VPA.
- Upper Bound (Limite supérieure) : limite supérieure à partir de laquelle le VPA déclenche un redimensionnement. Si l'utilisation du pod dépasse cette limite, le VPA supprime le pod et le fait évoluer à la hausse.
Vous remarquerez que le VPA recommande de réduire la demande de processeur pour ce conteneur à 25m (millicœurs), contre 100m précédemment, et vous suggère aussi une valeur pour la demande de mémoire. À ce stade, vous pouvez appliquer manuellement ces recommandations au déploiement hello-server.
Pour voir le VPA en action et ses effets dans cet atelier, vous allez définir la règle de mise à jour de hello-vpa sur Auto et observer le scaling.
Modifiez le fichier manifeste pour définir la règle sur Auto et appliquez la configuration :
sed -i 's/Off/Auto/g' hello-vpa.yaml
kubectl apply -f hello-vpa.yaml
Pour redimensionner un pod, le VPA doit supprimer le pod en question et le recréer aux nouvelles dimensions. Par défaut, pour éviter les temps d'arrêt, le VPA ne supprime et ne redimensionne pas le dernier pod actif. C'est pourquoi vous devez disposer d'au moins deux instances dupliquées pour voir le VPA effectuer des modifications.
Faites évoluer le déploiement hello-server à deux instances dupliquées :
kubectl scale deployment hello-server --replicas=2
Vous pouvez maintenant observer vos pods :
kubectl get pods -w
Attendez que les pods hello-server-xxx affichent l'état terminating (Arrêt en cours) :

Cela indique que votre VPA supprime et redimensionne les pods. Une fois l'état apparu, appuyez sur Ctrl+C pour quitter la commande.
Cliquez sur Check my progress (Vérifier ma progression) pour valider que vous avez correctement effectué la tâche ci-dessus.
Résultats du HPA
À ce stade, votre HPA aura probablement réduit le nombre d'instances dupliquées de votre déploiement php-apache.
Exécutez la commande suivante pour vérifier votre HPA :
kubectl get hpa
Consultez la colonne Replicas (Instances dupliquées). Vous constaterez que votre déploiement php-apache ne comprend plus qu'un pod.
Le HPA supprime également toutes les ressources inutilisées, puisque l'application est actuellement inactive. Cependant, si la demande de l'application php-apache venait à augmenter, il effectuerait un scaling inverse pour traiter la nouvelle charge.
Il s'agit d'une précaution très judicieuse pour optimiser les coûts. Avec un autoscaler bien réglé, vous êtes sûr de fournir une application à haute disponibilité et de ne payer que les ressources requises pour assurer une telle disponibilité, quelle que soit la demande.
Résultats du VPA
Les pods du déploiement hello-server devraient maintenant être redimensionnés. Examinez vos pods :
kubectl describe pod hello-server | sed -n "/Containers:$/,/Conditions:/p"
Recherchez le champ Requests (Demandes). Votre VPA a recréé les pods avec leurs utilisations cibles. Il doit maintenant demander moins de ressources de processeur et une certaine quantité de mémoire :

Ainsi, le VPA devient un excellent outil pour optimiser l'utilisation des ressources, et donc les coûts. La demande de processeur initiale de 400 millicœurs dépassait la puissance nécessaire au conteneur. En ajustant la demande aux 25 millicœurs recommandés, vous utilisez moins de processeur sur le pool de nœuds, ce qui pourrait réduire le nombre de nœuds à provisionner dans le cluster.
Si la règle de mise à jour était définie sur Auto, le VPA supprimerait et redimensionnerait sans arrêt les pods du déploiement hello-server tout au long de sa durée de vie. Il ferait évoluer les pods à la hausse par des demandes plus importantes pour traiter un trafic dense, puis à la baisse lors des périodes creuses. Cela peut être utile pour gérer une augmentation constante de la demande de votre application, mais peut s'avérer risqué en termes de disponibilité en cas de pics importants.
De manière générale, il est préférable d'utiliser le VPA avec une règle de mise à jour sur Off (Désactivée) et d'appliquer les recommandations en fonction des besoins pour optimiser l'utilisation des ressources et maximiser la disponibilité du cluster.
Dans les sections suivantes, vous allez apprendre à optimiser encore davantage votre utilisation des ressources grâce à l'autoscaler de cluster et au provisionnement automatique des nœuds.
Autoscaler de cluster
L'autoscaler de cluster est conçu pour ajouter ou supprimer des nœuds en fonction de la demande. Lorsque la demande est élevée, l'autoscaler de cluster ajoute des nœuds au pool pour répondre à cette demande. Lorsque la demande est faible, l'autoscaler de cluster réduit le nombre de nœuds en supprimant des nœuds. Ainsi, vous assurez la haute disponibilité de votre cluster tout en réduisant au mieux les coûts superflus associés aux machines supplémentaires.
Activez l'autoscaling pour votre cluster :
gcloud beta container clusters update scaling-demo --enable-autoscaling --min-nodes 1 --max-nodes 5
Cette opération prend quelques minutes.
Lors du scaling d'un cluster, la décision de supprimer un nœud relève d'un compromis entre optimisation de l'utilisation et disponibilité des ressources. Supprimer les nœuds sous-exploités améliore l'utilisation du cluster, mais les nouvelles charges de travail peuvent se trouver contraintes d'attendre le provisionnement de nouvelles ressources avant de pouvoir s'exécuter.
Vous pouvez spécifier le profil d'autoscaling à utiliser pour prendre de telles décisions. Les profils actuellement disponibles sont les suivants :
- Balanced (Équilibré) : profil par défaut.
- Optimize-utilization (Optimiser l'utilisation) : permet d'optimiser l'utilisation plutôt que de conserver les ressources dans le cluster. Lorsque ce profil est sélectionné, l'autoscaler réduit plus radicalement les ressources du cluster. Il peut supprimer davantage de nœuds et supprimer les nœuds plus rapidement. Ce profil est optimisé pour l'utilisation avec des charges de travail par lots, qui ne sont pas sensibles à la latence de démarrage.
Passez au profil d'autoscaling optimize-utilization (Optimiser l'utilisation) afin de pouvoir observer tous les effets du scaling :
gcloud beta container clusters update scaling-demo \
--autoscaling-profile optimize-utilization
Une fois l'autoscaling activé, observez votre cluster dans Cloud Console. Cliquez sur les trois barres en haut à gauche pour ouvrir le menu de navigation.
Dans le menu de navigation, sélectionnez Kubernetes Engine > Clusters.
Sur la page Clusters, sélectionnez le cluster scaling-demo.
Sur la page du cluster scaling-demo, sélectionnez l'onglet Nodes (Nœuds) :

Regardez la présentation de l'utilisation des ressources par vos trois nœuds.

Si vous additionnez les valeurs CPU requested (Processeur demandé) et CPU allocatable (Processeur pouvant être alloué) pour les trois nœuds, les totaux sont respectivement 1 555 et 2 820 millicœurs. Cela signifie qu'un total de 1 265 millicœurs de processeur est disponible sur l'ensemble du cluster. Ce nombre est supérieur à ce qui pourrait être fourni par un nœud.
Pour optimiser l'utilisation, la charge de travail associée à la demande actuelle pourrait être concentrée sur deux nœuds au lieu de trois. Cependant, l'autoscaling du cluster à la baisse n'a pas encore été effectué. En effet, les pods système sont répartis sur l'ensemble du cluster.
Votre cluster exécute un certain nombre de déploiements dans l'espace de noms kube-system qui donne accès aux différents services de GKE tels que la journalisation, la surveillance et l'autoscaling, entre autres. Vous pouvez le vérifier en exécutant la commande suivante dans Cloud Shell :
kubectl get deployment -n kube-system
Par défaut, la plupart des pods système de ces déploiements n'autorisent pas l'autoscaler de cluster à les mettre complètement hors connexion pour les replanifier. Cette configuration est généralement souhaitable, car un grand nombre de ces pods collectent des données utilisées dans d'autres déploiements et services. Par exemple, l'interruption temporaire de metrics-agent ou l'arrêt du pod fluentd pourraient créer des lacunes dans les données collectées pour le VPA et le HPA ou dans vos journaux cloud, respectivement.
Pour les besoins de cet atelier, vous allez appliquer des budgets d'interruption à vos pods kube-system, ce qui permettra à l'autoscaler de cluster de les replanifier correctement sur un autre nœud. Ainsi, vous aurez assez d'espace pour procéder au scaling à la baisse de votre cluster.
Les budgets d'interruption de pod (PDB, Pod Disruption Budgets) indiquent comment Kubernetes doit gérer les interruptions, telles que les mises à niveau, suppressions de pods, manques de ressources, etc. Dans les PDB, vous pouvez spécifier les valeurs max-unavailable et/ou min-available (nombre maximal de pods indisponibles et/ou nombre minimal de pods disponibles) pour un déploiement.
Exécutez les commandes suivantes afin de créer un PDB pour chacun de vos pods kube-system :
kubectl create poddisruptionbudget kube-dns-pdb --namespace=kube-system --selector k8s-app=kube-dns --max-unavailable 1
kubectl create poddisruptionbudget prometheus-pdb --namespace=kube-system --selector k8s-app=prometheus-to-sd --max-unavailable 1
kubectl create poddisruptionbudget kube-proxy-pdb --namespace=kube-system --selector component=kube-proxy --max-unavailable 1
kubectl create poddisruptionbudget metrics-agent-pdb --namespace=kube-system --selector k8s-app=gke-metrics-agent --max-unavailable 1
kubectl create poddisruptionbudget metrics-server-pdb --namespace=kube-system --selector k8s-app=metrics-server --max-unavailable 1
kubectl create poddisruptionbudget fluentd-pdb --namespace=kube-system --selector k8s-app=fluentd-gke --max-unavailable 1
kubectl create poddisruptionbudget backend-pdb --namespace=kube-system --selector k8s-app=glbc --max-unavailable 1
kubectl create poddisruptionbudget kube-dns-autoscaler-pdb --namespace=kube-system --selector k8s-app=kube-dns-autoscaler --max-unavailable 1
kubectl create poddisruptionbudget stackdriver-pdb --namespace=kube-system --selector app=stackdriver-metadata-agent --max-unavailable 1
kubectl create poddisruptionbudget event-pdb --namespace=kube-system --selector k8s-app=event-exporter --max-unavailable 1
Cliquez sur Check my progress (Vérifier ma progression) pour valider que vous avez correctement effectué la tâche ci-dessus.
Dans chacune de ces commandes, vous sélectionnez un pod de déploiement kube-system à l'aide d'un libellé défini à la création du pod et vous spécifiez qu'il ne peut y avoir qu'un seul pod indisponible pour le déploiement concerné. L'autoscaler pourra ainsi replanifier les pods système.
Une fois les PDB actifs, votre cluster devrait opérer un scaling à la baisse, passant de trois à deux nœuds, en une ou deux minutes.
Exécutez à nouveau cette commande dans Cloud Shell jusqu'à ce qu'il n'y ait plus que deux nœuds en tout :
kubectl get nodes
Dans Cloud Console, actualisez l'onglet Nodes (Nœuds) de scaling-demo ou revenez sur cette page via ce lien pour examiner l'organisation de vos ressources :

L'autoscaling que vous avez configuré a réduit votre cluster de trois à deux nœuds.
En termes de coûts, ce scaling du pool de nœuds à la baisse vous permet d'avoir moins de machines à payer durant les périodes de faible demande sur votre cluster. Le scaling pourrait avoir encore plus d'impact si la demande variait fortement au cours de la journée.
Il est important de noter que, si l'autoscaler de cluster a supprimé le nœud superflu, ce sont le VPA et le HPA qui ont permis de réduire suffisamment la demande de processeur et rendu ce nœud inutile. Utilisés conjointement, ces outils sont un excellent moyen d'optimiser vos coûts globaux et votre utilisation des ressources.
Ainsi, l'autoscaler de cluster permet d'ajouter et de supprimer des nœuds en fonction des pods à planifier. Cependant, GKE fournit une autre fonctionnalité spécifique pour le scaling vertical : le provisionnement automatique des nœuds.
Provisionnement automatique des nœuds
Le provisionnement automatique des nœuds (NAP, Node Auto Provisionning) ajoute des pools de nœuds dimensionnés pour répondre à la demande. Sans NAP, l'autoscaler de cluster se contente de créer des nœuds dans les pools que vous avez spécifiés, c'est-à-dire que les nouvelles machines sont du même type que les autres nœuds du pool concerné. Cela permet d'optimiser l'utilisation des ressources pour des charges de travail par lots et des applications qui ne nécessitent pas un scaling extrême, car il est souvent plus long de créer un pool de nœuds optimisé pour un cas d'utilisation que d'ajouter des nœuds à un pool existant.
Activer le NPA :
gcloud container clusters update scaling-demo \
--enable-autoprovisioning \
--min-cpu 1 \
--min-memory 2 \
--max-cpu 45 \
--max-memory 160
Dans cette commande, vous spécifiez un minimum et un maximum pour vos ressources de processeur et de mémoire. Ces valeurs s'appliquent à l'ensemble du cluster.
Le NAP peut prendre un peu de temps, et il est fort probable qu'il ne crée pas de pool de nœuds pour le cluster scaling-demo dans son état actuel.
Dans les sections suivantes, vous allez accroître la demande sur votre cluster et observer l'action de vos autoscalers et du NAP.
Cliquez sur Check my progress (Vérifier ma progression) pour valider que vous avez correctement effectué la tâche ci-dessus.
Tester avec une demande plus importante
Jusqu'à présent, vous avez vu que le HPA, le VPA et l'autoscaler de cluster peuvent vous aider à limiter les ressources et vos coûts lorsque la demande de votre application est faible. Vous allez maintenant voir comment ces outils gèrent la disponibilité en cas de forte demande.
Ouvrez un nouvel onglet dans Cloud Shell en appuyant sur l'icône + :

Dans le nouvel onglet, exécutez la commande suivante pour envoyer une boucle infinie de requêtes au service php-apache :
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
Revenez à l'onglet Cloud Shell initial.
Patientez une minute environ, puis exécutez la commande suivante pour observer l'augmentation de la charge de processeur sur votre HPA :
kubectl get hpa
Patientez et réexécutez la commande jusqu'à ce que votre cible dépasse 100 %.

À présent, regardez comment votre cluster gère cette charge accrue en exécutant de manière répétée cette commande :
kubectl get deployment php-apache
Vous pouvez également surveiller votre cluster en actualisant l'onglet Nodes (Nœuds) dans Cloud Console. Vous pouvez aussi revenir à cet onglet en cliquant sur ce lien.
Au bout de quelques minutes, vous verrez plusieurs événements se produire.
- Tout d'abord, le HPA fera évoluer automatiquement le déploiement
php-apacheà la hausse pour gérer la charge supplémentaire. - Ensuite, l'autoscaler de cluster devra provisionner de nouveaux nœuds pour gérer l'augmentation de la demande.
- Enfin, le provisionnement automatique des nœuds créera un pool de nœuds optimisé pour les demandes de processeur et de mémoire associées aux charges de travail du cluster. Dans ce cas, il s'agira probablement d'un pool de nœuds doté d'un processeur puissant et d'une faible mémoire, car le test de charge dépasse les limites du processeur.
Attendez que le déploiement php-apache évolue à la hausse jusqu'à sept instances dupliquées et que l'onglet "Nodes" (Nœuds) ressemble à ceci :

Revenez à l'onglet Cloud Shell dans lequel vous avez exécuté le test de charge, puis arrêtez le test en appuyant sur Ctrl+C. Le cluster va maintenant évoluer à la baisse à mesure que la demande diminue.
Votre cluster a bien effectué un scaling à la hausse pour répondre à une demande plus importante ! Notez toutefois que le traitement de cette hausse de la demande a pris du temps. Pour beaucoup d'applications, la perte de disponibilité pendant le provisionnement de nouvelles ressources est un problème.
Optimiser les charges importantes
Lors d'un scaling à la hausse répondant à des charges plus importantes, le HPA ajoute des pods et le VPA les redimensionne en fonction de vos paramètres. Si un nœud existant a suffisamment d'espace, il pourra peut-être exécuter immédiatement l'application sur un nouveau pod, sans avoir à extraire l'image au préalable. Si vous travaillez avec un nœud qui n'a pas encore déployé votre application, l'opération prendra un peu plus de temps, car il devra télécharger les images du conteneur avant d'exécuter l'application.
Ainsi, si vous n'avez pas assez d'espace sur vos nœuds existants et que vous utilisez l'autoscaler de cluster, cela sera encore plus long. En effet, il devra provisionner un nœud, le configurer, puis télécharger l'image et démarrer les pods. Si le provisionnement automatique des nœuds crée un pool comme précédemment sur votre cluster, cela prendra encore plus de temps, car le provisionnement du pool viendra s'ajouter aux autres étapes de création du nœud.
Afin de gérer ces différentes latences d'autoscaling, vous avez intérêt à surprovisionner légèrement pour limiter la pression sur vos applications lors des autoscalings à la hausse. Cette démarche est très importante pour l'optimisation des coûts, car vous ne souhaitez pas payer plus de ressources que nécessaire, ni détériorer les performances de vos applications.
Pour déterminer le niveau de surprovisionnement requis, vous pouvez appliquer la formule suivante :

À titre d'exemple, pensez à l'utilisation du processeur sur votre cluster. Vous ne voulez pas qu'elle atteigne 100 %. Vous pouvez donc choisir une marge de sécurité de 15 %. La variable de trafic de la formule correspond alors au pourcentage estimé de croissance du trafic dans les deux à trois minutes qui suivent. Dans le test de charge précédemment exécuté, la fourchette de 0 à 150 % était quelque peu exagérée. Optez plutôt pour une augmentation moyenne du trafic de 30 %.
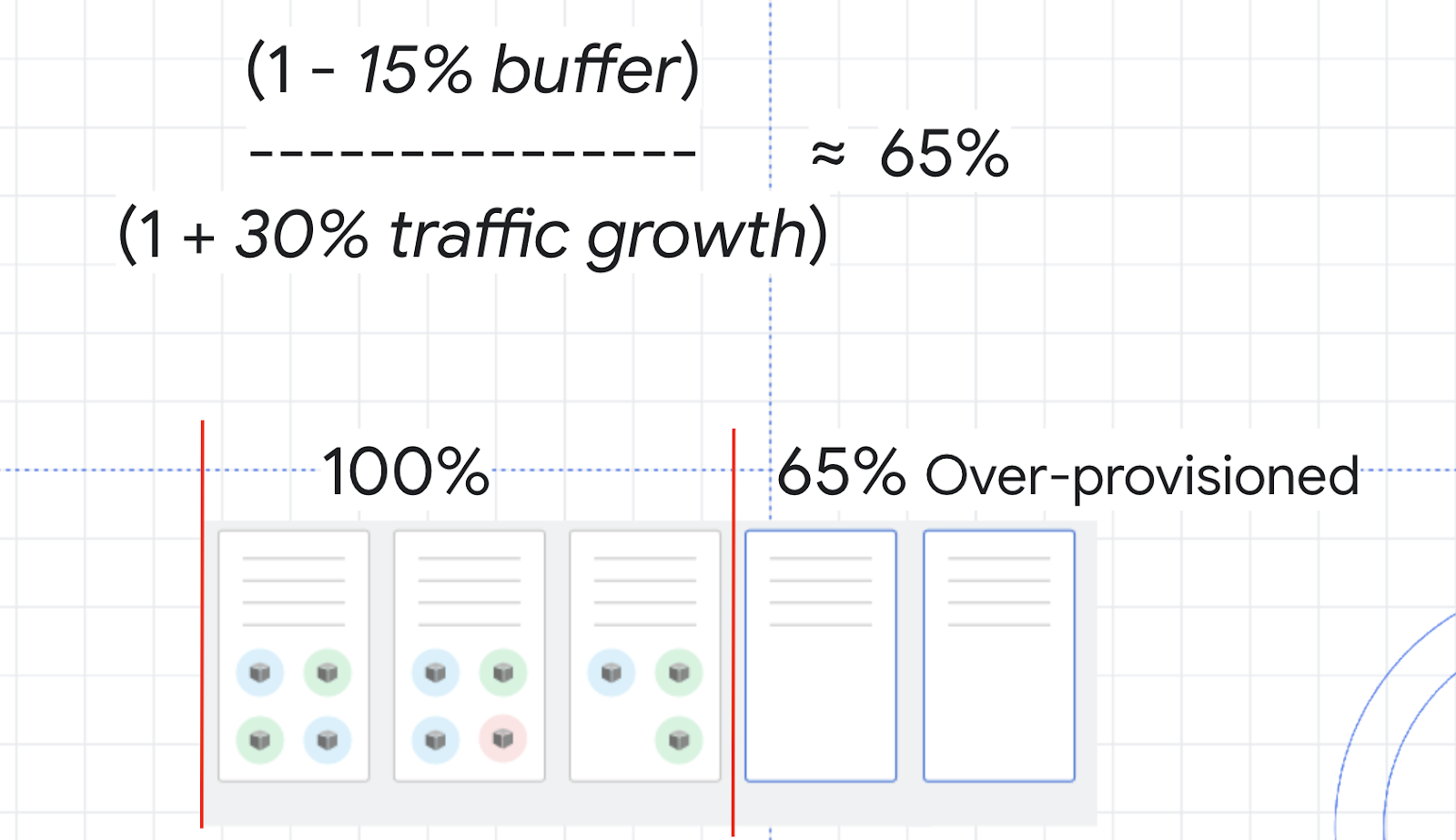
Avec ces chiffres, le calcul vous donne une marge de sécurité d'environ 65 %. Cela signifie que vous devez surprovisionner vos ressources d'environ 65 % pour pouvoir traiter les scalings à la hausse sans problème majeur.
Une stratégie efficace pour surprovisionner un cluster par autoscaling consiste à utiliser des pods de pause.
Les pods de pause sont des déploiements de faible priorité qui peuvent être supprimés et remplacés par des déploiements de priorité élevée. Ainsi, vous pouvez créer des pods de faible priorité qui n'ont aucune fonction, si ce n'est d'occuper un espace tampon. Lorsque le pod de priorité élevée a besoin d'espace, les pods de pause sont supprimés et replanifiés sur un autre nœud ou sur un nouveau nœud, ce qui libère un espace pour planifier rapidement le pod de priorité élevée.
Créez un fichier manifeste pour un pod de pause :
cat << EOF > pause-pod.yaml
---
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: reserve-resources
image: k8s.gcr.io/pause
resources:
requests:
cpu: 1
memory: 4Gi
EOF
Appliquez-le à votre cluster :
kubectl apply -f pause-pod.yaml
Maintenant, attendez une minute, puis actualisez l'onglet Nodes (Nœuds) de votre cluster scaling-demo. Si vous avez fermé cet onglet, cliquez ici pour y accéder de nouveau.
Observez la création du nœud, probablement dans un nouveau pool de nœuds, qui va accueillir le pod de pause que vous venez de créer. Si vous exécutez à nouveau le test de charge et que votre déploiement php-apache requiert un nœud supplémentaire, celui-ci pourra être planifié sur le nœud contenant votre pod de pause, et le pod de pause sera placé sur un nouveau nœud. Cette stratégie est excellente. Grâce aux pods de pause, le cluster provisionne un nouveau nœud à l'avance, et votre application peut évoluer à la hausse beaucoup plus rapidement. Si vous attendez une augmentation du trafic, vous pouvez ajouter des pods de pause supplémentaires, mais il est recommandé de ne pas ajouter plus d'un pod de pause par nœud.
Cliquez sur Check my progress (Vérifier ma progression) pour valider que vous avez correctement effectué la tâche ci-dessus.
Félicitations !
Vous avez configuré un cluster capable d'évoluer automatiquement à la hausse ou à la baisse en fonction de la demande. L'autoscaling horizontal et l'autoscaling vertical font évoluer automatiquement les déploiements de votre cluster, tandis que l'autoscaler de cluster et le provisionnement automatique des nœuds font évoluer automatiquement l'infrastructure du cluster.
Comme toujours, c'est la charge de travail qui détermine les outils à employer. Une utilisation judicieuse de ces autoscalers peut vous permettre d'optimiser la disponibilité quand vous en avez besoin et de ne payer que pour les ressources nécessaires lorsque la demande est faible. Ainsi, vous optimisez votre utilisation des ressources et vous faites des économies en réduisant les coûts.

Terminer votre quête
Cet atelier d'auto-formation fait partie de la quête Qwiklabs Optimize Costs for Google Kubernetes Engine.
Une quête est une série d'ateliers associés qui constituent une formation. Si vous terminez cette quête, vous obtiendrez le badge ci-dessus attestant de votre réussite.
Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux.
Inscrivez-vous à cette quête pour obtenir immédiatement les crédits associés à cet atelier si vous l'avez suivi.
Découvrez les autres quêtes Qwiklabs disponibles.
Atelier suivant
Continuez sur votre lancée en suivant l'atelier Optimisation de la charge de travail GKE, ou consultez ces suggestions :
Étapes suivantes et informations supplémentaires
- Bonnes pratiques pour l'exécution d'applications Kubernetes à coût maîtrisé sur GKE : Ajuster l'autoscaling GKE
- Documentation de l'autoscaler de cluster
- Documentation de l'autoscaler de pods horizontal
- Documentation de l'autoscaler de pods vertical
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 25 février 2022
Dernier test de l'atelier : 25 février 2022
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.