チェックポイント
Explore the NYC Citi Bike Trips dataset
/ 20
Cleaned training data
/ 20
Training a Model
/ 20
Evaluate the time series model
/ 20
Make Predictions using the model
/ 20
BigQuery ML を使用した需要予測の構築
GSP852

概要
BigQuery は、Google が低価格で提供する NoOps のフルマネージド分析データベースです。テラバイト単位の大規模なデータをクエリすることが可能で、インフラストラクチャを所有して管理したりデータベース管理者を配置したりする必要はありません。
BigQuery の機能である BigQuery ML(BQML)を使用すれば、最小限のコーディングで ML モデルの作成、トレーニング、評価、予測が可能になります。詳しくは、こちらの BigQuery ML の動画をご覧ください。
このラボでは BQML を使用して、複数の商品の需要を予測する時系列モデルを構築する方法を学びます。NYC Citi Bike Trips という一般公開データセットを使用して、過去のデータから次の 30 日間の需要を予測する方法について学習します。自転車を小売の販売商品、自転車ステーションを店舗だと考えてください。
こちらの動画を視聴して、需要予測のサンプル ユースケースを確認してください。
目標
このラボでは、次のタスクの実行方法について学びます。
- BigQuery を使用して一般公開データセットを見つける。
- 一般公開データセット
NYC Citi Bike Tripsに対してクエリを実行して探索する。 - バッチ予測に使用するトレーニングと評価のデータセットを作成する。
- BQML で予測(時系列)モデルを作成する。
- 機械学習モデルの性能を評価する。
環境を設定する
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

BigQuery コンソールを開く
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
- [完了] をクリックします。
BigQuery コンソールが開きます。
タスク 1. NYC Citi Bike Trips データセットの探索
ニューヨーク市の自転車の移動に関する一般公開データセットを使用します。 このデータセットには Google Cloud コンソール内の Marketplace でアクセスできます。 BigQuery なら、[エクスプローラ] インターフェースから一般公開データセットに直接アクセスできて簡単です。
- [追加] を選択します。
![[+ データを追加] ボタンの周囲に緑色の四角形が表示されている、BigQuery の [エクスプローラ] ページ](https://cdn.qwiklabs.com/S9hwfI0WN98YH2Mx9EchRMKUiI1l1272pLFAVwiwEU4%3D)
-
[その他のソース] にある [公開データセット] を選択します。
-
「bikes」で検索して、NYC Citi Bike Trips タイルをクリックします。
- [データセットを表示] ボタンをクリックして、BigQuery でデータセットを開きます。
![[データセットを表示] ボタンが表示されている NYC Citi Bike Trips のポップアップ](https://cdn.qwiklabs.com/MwlhN0mSmKBXT6dhUoxBuzpruONCasDVuORW5xgt8mY%3D)
問題: ニューヨーク市で自転車を借りられる場所をいくつか挙げてください。
次は、この問題に答えられるようにクエリを実行します。
- エディタタブをクリックして、次の SQL コードをクエリエディタに追加します。
- [実行] をクリックします。
- 次のようなテーブル構造が表示されます。
| 行 | bikeid | starttime | start_station_name | end_station_name |
|---|---|---|---|---|
| 1 | 18447 | 2013-09-16T19:22:43 | 9 Ave & W 22 St | W 27 St & 7 Ave |
| 2 | 22598 | 2015-12-30T13:02:38 | E 10 St & 5 Ave | W 11 St & 6 Ave |
| 3 | 28833 | 2017-09-02T16:27:37 | Washington Pl & Broadway | Lexington Ave & E 29 St |
| 4 | 21338 | 2017-11-15T06:57:09 | Hudson St & Reade St | Centre St & Chambers St |
| 5 | 19888 | 2013-11-07T15:12:07 | W 42 St & 8 Ave | W 56 St & 6 Ave |
これは、ニューヨーク市で自転車を借りられるステーションの場所を示すリストです。これで、NYC Citi Bike Trips データセットに対してクエリを実行する方法がわかりました。
完了したタスクをテストする
BigQuery はデータを通じて問題の答えを得るのに適したツールです。 クエリ構文を学習することで、データを通じて分析情報を取得できるようになります。
今実行したクエリについて考えてみましょう。
別のタイプのクエリを試してみます。データセットをフィルタして、より詳細な情報を表示させた方がよいユースケースもあるかもしれません。
次の例では、BigQuery を使用して期間を指定しています。
- 前のクエリを次のように置き換えます。
- [実行] をクリックします。
次のような結果が返されます。
| 行 | start_date | start_station_id | total_trips |
|---|---|---|---|
| 1 | 2016-01-27 | 3119 | 15 |
| 2 | 2016-04-07 | 3140 | 83 |
| 3 | 2016-08-15 | 254 | 109 |
| 4 | 2016-05-10 | 116 | 217 |
| 5 | 2016-07-07 | 268 | 151 |
これで、クエリ結果を期間でフィルタする方法がわかりました。
完了したタスクをテストする
クエリを作成するにはデータを操作するコマンドの学習が必要です。 2 つ目のクエリでは、日付とステーション名で自転車の利用をグループ化できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 2. クリーンアップしたトレーニング データ
2 つ目のクエリでは、日付と出発ステーションが同じ行を 1 つにまとめ、その日の自転車の利用数を得ました。このデータはテーブルまたはビューとして保存できます。
次のセクションでは、トレーニング データで次の構造を作ります。
| 種類 | 名前 |
|---|---|
| データセット | bqmlforecast |
| テーブル | training_data |
データセットを作成する
- 「Qwiklabs」で始まるプロジェクトの横にある「アクションを表示」アイコンをクリックし、[データセットを作成] ボタンを表示します。
- [データセットを作成] を選択します。
- データセット名として「
bqmlforecast」と入力します。 - [テーブルの有効期限を有効にする] ボックスをオンにして、[
デフォルトのテーブル最長存続期間] に 1 日と入力します。 - [データセットを作成] ボタンを選択します。
これで、自分のデータをホストするデータセットを用意できました。
テーブルを作成する
この時点では作成済みのデータはありません。クエリを実行して結果をテーブルに保存し、この状況を修正します。
- [クエリを新規作成] ボタンをクリックします。
- 次のクエリを実行してデータを生成します。
IN 句では、トレーニング データを減らすために、モデルに含めるステーションを 5 つだけ選択しています。すべてを含んだモデルをトレーニングするには、このラボよりも多くの時間が必要になります。このクエリはモデルをトレーニングする際の基礎として使用できます。
- [
結果を保存] を選択します。 - プルダウン メニューで [BigQuery テーブル] を選択します。
- [データセット] には [bqmlforecast] を選択します。
- [テーブル] には「
training_data」という名前を追加します。 - [エクスポート] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 3. モデルのトレーニング
次のクエリでは、トレーニング データを使用して ML モデルを作成します。 作成したモデルを使用すると、需要予測を実行できるようになります。
ARIMA アルゴリズムを使用しています。
利用可能な他のアルゴリズムについては、BigQuery ML のドキュメントをご覧ください。
- 次のクエリをエディタに入力します。
- [実行] をクリックしてトレーニングを開始します。
- BigQuery によるモデルのトレーニングが開始されます。トレーニングの完了には約 2 分かかります。待っている間に、ここで行われている処理の内容について確認しておきましょう。
BigQuery ML で時系列モデルをトレーニングする場合、複数のモデル / コンポーネントがモデル作成パイプラインで使用されます。ARIMA は、BigQuery ML で利用可能なコア アルゴリズムの一つです。
以下、使用されるコンポーネントをおおむね実行される順序で列挙します。
- 事前加工: 入力時系列に対する自動クリーニング調整。欠損値、タイムスタンプの重複、異常値の急増などを調整します。また、時系列履歴の急激なレベル変更にも対応します。
-
祝日効果: BigQuery ML で時系列モデルを作成する場合は、祝日効果を加味することもできます。デフォルトでは、祝日効果のモデリングは無効になっています。ただし、このデータは米国のデータであり、最小限である 1 年分の日次データがあるため、任意の
HOLIDAY_REGIONを指定することもできます。祝日効果を有効にすると、祝日に見られる異常な増大と減少が異常として処理されなくなります。利用できる地域の一覧については、ドキュメントのHOLIDAY_REGIONをご覧ください。 -
季節変動と長期変動の分解:
LOgical regrESSion(Loess STL)アルゴリズムによる季節変動と長期変動の分解を使用します。二重指数平滑(ETS)アルゴリズムを使用した季節性の推定。 -
トレンド モデリング: ARIMA モデルと auto.ARIMA アルゴリズムを使用して、ハイパーパラメータを自動調整します。auto.ARIMA では、p、d、q、ドリフトなど、多くの候補モデルが並行してトレーニング、評価されます。
赤池情報量規準(AIC)が最も低いモデルが最適なモデルになります。
時系列モデルをトレーニングして 1 つの商品の需要を予測することも、複数の商品の需要を同時に予測することもできます(予測する商品が何千点、何百万点もある場合には非常に便利です)。
複数の商品の需要を同時に予測する場合は、複数のパイプラインが並行して実行されます。
この例では、1 つのモデル作成文で複数のステーションについてモデルをトレーニングしているため、TIME_SERIES_ID_COL というパラメータを start_station として指定する必要があります。
![[モデルの詳細] セクションと [トレーニング オプション] セクションが表示されている、bike_model の [詳細] タブページ](https://cdn.qwiklabs.com/AnC2IAc2lQxkFqQ%2FFSC%2B7jt9PIzbC1L4BerJuDQHuE0%3D)
1 つのアイテムの需要のみを予測する場合は、TIME_SERIES_ID_COL を指定する必要はありません。
モデルのトレーニングが正常に完了したら、緑色のチェックマークが表示されます。これで、完成したモデルを使用して予測を実行できます。
モデルのトレーニングにまだ時間がかかっている場合は、こちらの YouTube 動画をご覧ください。別のデータセットを使用して、このラボと同様の需要予測ソリューションを構築してデプロイする方法を説明しています。このラボは一定の時間内に完了する必要があるので、必ず戻ってきてください。
- トレーニング ジョブが完了したら、結果タブの [
モデルに移動] をクリックします。
今実行したクエリについて考えてみましょう。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 4. 時系列モデルの評価
こちらの動画を見て、BigQuery ML における時系列モデルの仕組みを理解してください。
作成したモデルにはクエリを実行できます。前のクエリをベースにして、新しいモデルが利用できるようになりました。ML.EVALUATE 関数を使用すると、作成されたすべてのモデルの評価指標(モデルごとに 1 行)を確認できます。
- 先ほど作成した時系列モデルに対してクエリを実行します。
上のクエリを実行すると、下の画像のような結果が表示されます。
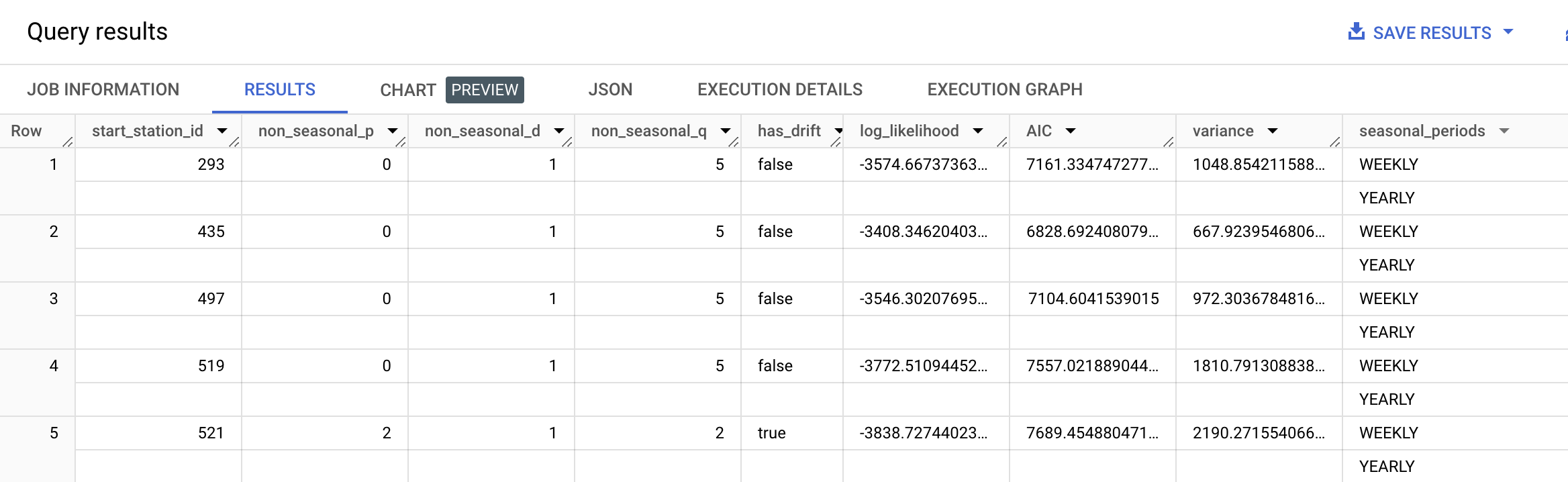
トレーニング データに含まれているステーションごとに 1 つ、合計 5 つのトレーニングされたモデルがあります。
- 最初の 4 列(
non_seasonal_{p,d,q}、has_drift)は、ARIMA モデルの定義です。 - その後の 3 つの指標(
log_likelihood、AIC、variance)は、ARIMA モデルの適合プロセスに関連するものです。
適合プロセスでは、時系列ごとに auto.ARIMA アルゴリズムが使用され、最適な ARIMA モデルが決定されます。 これらの指標のうち、通常は AIC を最もよく使用します。AIC は、時系列モデルがデータにどれだけ適合するかを評価するための指標で、複雑すぎるモデルにはペナルティを与えます。
最後に、5 つのステーションで検出された seasonal_periods が WEEKLY と YEARLY で定義されています。
別の質問も試してみましょう。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 5. モデルを使用した予測の実行
期間に設定された以降の n 個の値を予測する ML.FORECAST を使用して、予測を行います。
また、予測値が予測区間内に収まる割合である confidence_level を変更することもできます。
下のコードでは予測期間が「30」となっています。トレーニング データは日次データだったので、これは次の 30 日間の予測を行うことを意味します。
- 次のコードを実行し、トレーニング済みモデルを使用して次の 30 日間の予測を行います。
- 次のように表示されたら、2 番目の [
結果を表示] をクリックします。
![2 件のジョブが表示されている [すべての結果] ページ](https://cdn.qwiklabs.com/bmQt1HbRGV8vu7YqEcN7H151eLveWppB8hPqOUULIUE%3D)
次のような結果が表示されます。
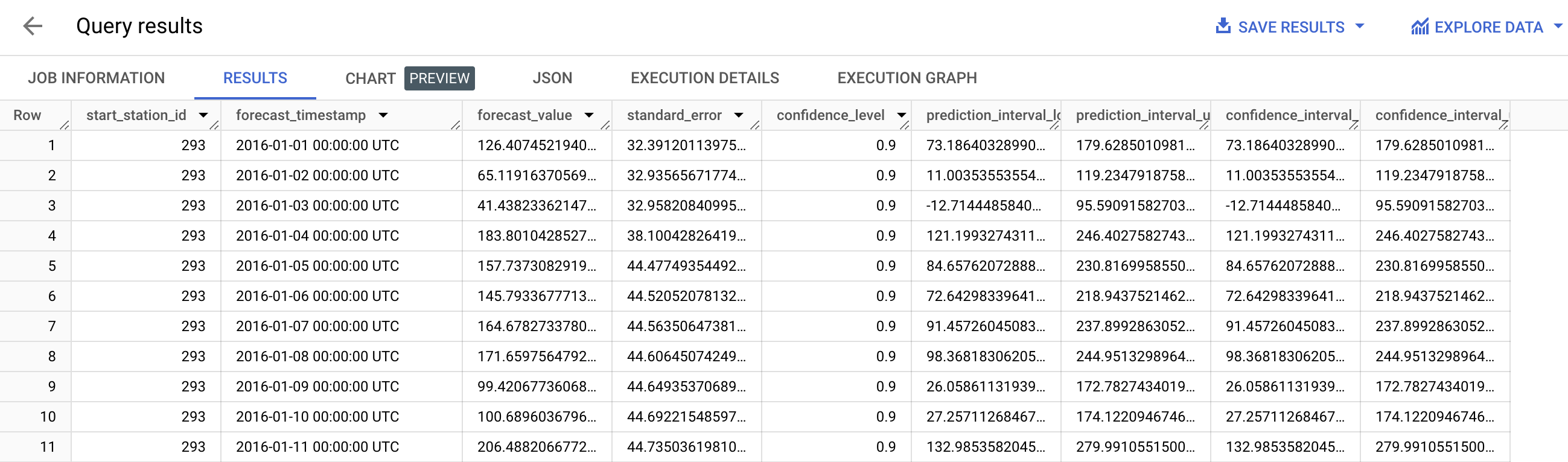
confidence_level が与えられた場合の prediction_interval の上限と下限も表示されます。
SQL スクリプトでは、期間と confidence_level の入力をパラメータ化できるよう、DECLARE と EXECUTE IMMEDIATE を使用しています。
HORIZON 変数と CONFIDENCE_LEVEL 変数を使用すると、後で値をより簡単に調整できるため、コードの可読性と保守性を向上させることができます。この構文の動作について詳しくは、クエリ構文のリファレンスをご覧ください。
今実行したクエリについて考えてみましょう。
上で説明したクエリのほかに、BigQuery ML ではクエリのスケジューリングもサポートされています。スケジュールされたクエリについて詳しくは、スケジュールされたクエリを使用したモデルの再トレーニングのスケジューリングと自動化についての動画をご覧ください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 6. 探索できるその他のデータセット
-
シカゴのタクシー運賃の予測など、他のデータセットに対してモデルを作成するには、以下のリンクから、bigquery-public-data を自分のプロジェクトに追加します。
お疲れさまでした
需要予測を実行するための ML モデルを BigQuery で構築できました。
クエストを完了する
このセルフペース ラボは、「Applying BQML's Classification, Regression, and Demand forecasting for Retail Applications」クエストの一部です。クエストとは学習プログラムを構成する一連のラボのことで、完了すると成果が認められてバッジが贈られます。バッジは公開して、オンライン レジュメやソーシャル メディア アカウントにリンクできます。クエストに登録すると、すぐにクレジットを受け取ることができます。受講可能なすべてのクエストについては、Google Cloud Skills Boost カタログをご覧ください。
次のステップと詳細情報
このテーマについてデベロッパー アドボケイト Polong Lin が説明しています。詳しくは以下をご覧ください。
- YouTube - How to build and deploy a demand forecasting solution with BigQuery ML(BigQuery ML を使用して需要予測ソリューションを構築・デプロイする方法)(12 分)
- Google Cloud ブログ - BigQuery ML で需要予測モデルを構築する方法
需要予測の別のユースケースを紹介します。
- Towards Data Science のブログ - How to do time series forecasting in BigQuery(BigQuery で時系列の予測を行う方法)
このラボで使用したツールの詳細は以下で確認できます。
- BigQuery ドキュメント
- ML については、AI Platform のドキュメントを参照してください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 10 月 3 日
ラボの最終テスト日: 2023 年 10 月 5 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。