Puntos de control
Create a Cloud Storage bucket
/ 25
Create Cloud Composer environment
/ 25
Uploading the DAG to Cloud Storage
/ 25
Exploring DAG runs
/ 25
Cloud Composer: Qwik Start - Consola
- GSP261
- Descripción general
- Objetivos
- Configuración y requisitos
- Tarea 1: Crea el entorno de Cloud Composer
- Tarea 2: Airflow y conceptos básicos
- Tarea 3: Define el flujo de trabajo
- Tarea 4: Consulta información del entorno
- Tarea 5: Usa la IU de Airflow
- Tarea 6: Configura variables de Airflow
- Tarea 7: Sube el DAG a Cloud Storage
- Pon a prueba tus conocimientos
- Borre el entorno de Cloud Composer
- ¡Felicitaciones!
- Próximos pasos
GSP261

Descripción general
Los flujos de trabajo son un tema recurrente en las estadísticas de datos. Implican transferir, transformar y analizar datos para descubrir la información significativa que contienen. En Google Cloud, la herramienta destinada a alojar flujos de trabajo es Cloud Composer, que es una versión alojada de Apache Airflow, la popular herramienta de código abierto para flujos de trabajo.
En este lab, usarás la consola de Cloud para configurar un entorno de Cloud Composer. Luego, utilizarás Cloud Composer para preparar un flujo de trabajo simple que verifique la existencia de un archivo de datos, cree un clúster de Cloud Dataproc, ejecute un trabajo de conteo de palabras de Apache Hadoop en el clúster de Cloud Dataproc y borre este clúster más adelante.
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
- Usar la consola de Cloud para crear el entorno de Cloud Composer
- Ver y ejecutar el DAG (grafo acíclico dirigido) en la interfaz web de Airflow
- Ver los resultados del trabajo de recuento de palabras en Storage
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar su lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab que tiene estos elementos:
- El botón Abrir la consola de Google
- Tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haga clic en Abrir la consola de Google. El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ve el diálogo Elegir una cuenta, haga clic en Usar otra cuenta. -
Si es necesario, copie el nombre de usuario del panel Detalles del lab y péguelo en el cuadro de diálogo Acceder. Haga clic en Siguiente.
-
Copie la contraseña del panel Detalles del lab y péguela en el cuadro de diálogo de bienvenida. Haga clic en Siguiente.
Importante: Debe usar las credenciales del panel de la izquierda. No use sus credenciales de Google Cloud Skills Boost. Nota: Usar su propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepte los términos y condiciones.
- No agregue opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No se registre para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Cloud en esta pestaña.

Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
- Haz clic en Activar Cloud Shell
en la parte superior de la consola de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. El resultado contiene una línea que declara el PROJECT_ID para esta sesión:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
-
Haz clic en Autorizar.
-
Ahora, el resultado debería verse de la siguiente manera:
Resultado:
- Puedes solicitar el ID del proyecto con este comando (opcional):
Resultado:
Resultado de ejemplo:
gcloud, consulta la guía con la descripción general de gcloud CLI en Google Cloud.
Tarea 1: Crea el entorno de Cloud Composer
En esta sección, crearás un entorno de Cloud Composer.
-
Ve a Menú de navegación (
) > Composer.
-
Haz clic en CREAR ENTORNO y selecciona Composer 1 del menú desplegable.
-
Establece lo siguiente para el entorno:
-
Nombre:
highcpu -
Ubicación:
-
Versión de la imagen: La más reciente
-
Zona:
-
Tipo de máquina:
e2-standard-2
-
Deja el resto de la configuración con sus valores predeterminados.
- Haz clic en CREAR.
El proceso de creación del entorno se completa cuando, en la página Entornos de la consola de Cloud, la marca de verificación verde aparece a la izquierda del nombre del entorno.
El entorno puede tardar entre 10 y 15 minutos en completar el proceso de configuración. Continúa con el lab mientras se inicia.
Crea un bucket de Cloud Storage
Crea un bucket de Cloud Storage en tu proyecto. Este bucket almacenará el resultado del trabajo de Hadoop obtenido de Dataproc.
-
Ve a Menú de navegación > Cloud Storage > Buckets y, luego, haz clic en CREAR.
-
Asígnale al bucket un nombre
, configúralo en una región y haz clic en CREAR.
Recuerda el nombre del bucket de Cloud Storage (tu ID del proyecto) ya que lo usarás como variable de Airflow más adelante en el lab.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 2: Airflow y conceptos básicos
Mientras esperas a que se cree tu entorno de Composer, repasa algunos términos que se usan con Airflow.
Airflow es una plataforma para crear, programar y supervisar flujos de trabajo de forma programática.
Utiliza Airflow para crear flujos de trabajo como grafos acíclicos dirigidos (DAG) de tareas. El programador de Airflow ejecuta tus tareas en un array de trabajadores mientras sigue las dependencias especificadas.
Conceptos básicos
Un grafo acíclico dirigido es una colección de todas las tareas que deseas ejecutar, organizadas de manera que reflejen sus relaciones y dependencias.
Es la descripción de una sola tarea; suele ser atómico. Por ejemplo, BashOperator se usa para ejecutar el comando Bash.
Es una instancia parametrizada de un operador; un nodo del DAG.
Es una ejecución específica de una tarea, caracterizada como un DAG, una tarea y un punto en el tiempo. Tiene un estado indicativo: running, success, failed, skipped, etcétera.
Puedes obtener más información sobre los conceptos en la documentación correspondiente.
Tarea 3: Define el flujo de trabajo
Ahora, analicemos el flujo de trabajo que utilizarás. Los flujos de trabajo de Cloud Composer constan de DAG (grafos acíclicos dirigidos). Los DAG se definen en archivos estándar de Python ubicados en la carpeta DAG_FOLDER de Airflow. Este, a su vez, ejecutará el código en cada archivo para compilar dinámicamente los objetos DAG. Puedes tener tantos DAG como desees, pues cada uno describe un número arbitrario de tareas. En general, cada DAG debe corresponder a un único flujo de trabajo lógico.
-
Haz clic en el ícono Activar Cloud Shell en la esquina superior derecha de la consola de Cloud para abrir una nueva ventana de Cloud Shell.
-
En Cloud Shell, usa nano (un editor de código) para crear el archivo
hadoop_tutorial.py:
- El siguiente código corresponde al flujo de trabajo hadoop_tutorial.py, que también se conoce como el DAG. Pega el siguiente código en el archivo
hadoop_tutorial.py.
- Presiona Ctrl + O, Intro y Ctrl + X, en ese orden, para guardar los cambios y salir de nano.
Para organizar las tres tareas del flujo de trabajo, el DAG importa los siguientes operadores:
-
DataprocClusterCreateOperator: Crea un clúster de Cloud Dataproc. -
DataProcHadoopOperator: Envía un trabajo de conteo de palabras de Hadoop y escribe los resultados en un bucket de Cloud Storage. -
DataprocClusterDeleteOperator: Borra el clúster para no generar cargos continuos de Compute Engine.
Las tareas se ejecutan de forma secuencial, lo que puedes ver en esta sección del archivo:
El nombre del DAG es hadoop_tutorial, y este se ejecuta una vez por día:
Dado que la start_date que se pasa a default_dag_args está establecida como yesterday, Cloud Composer programa el flujo de trabajo para que comience inmediatamente después de subir el DAG.
Tarea 4: Consulta información del entorno
-
Vuelve a Composer para comprobar el estado de tu entorno.
-
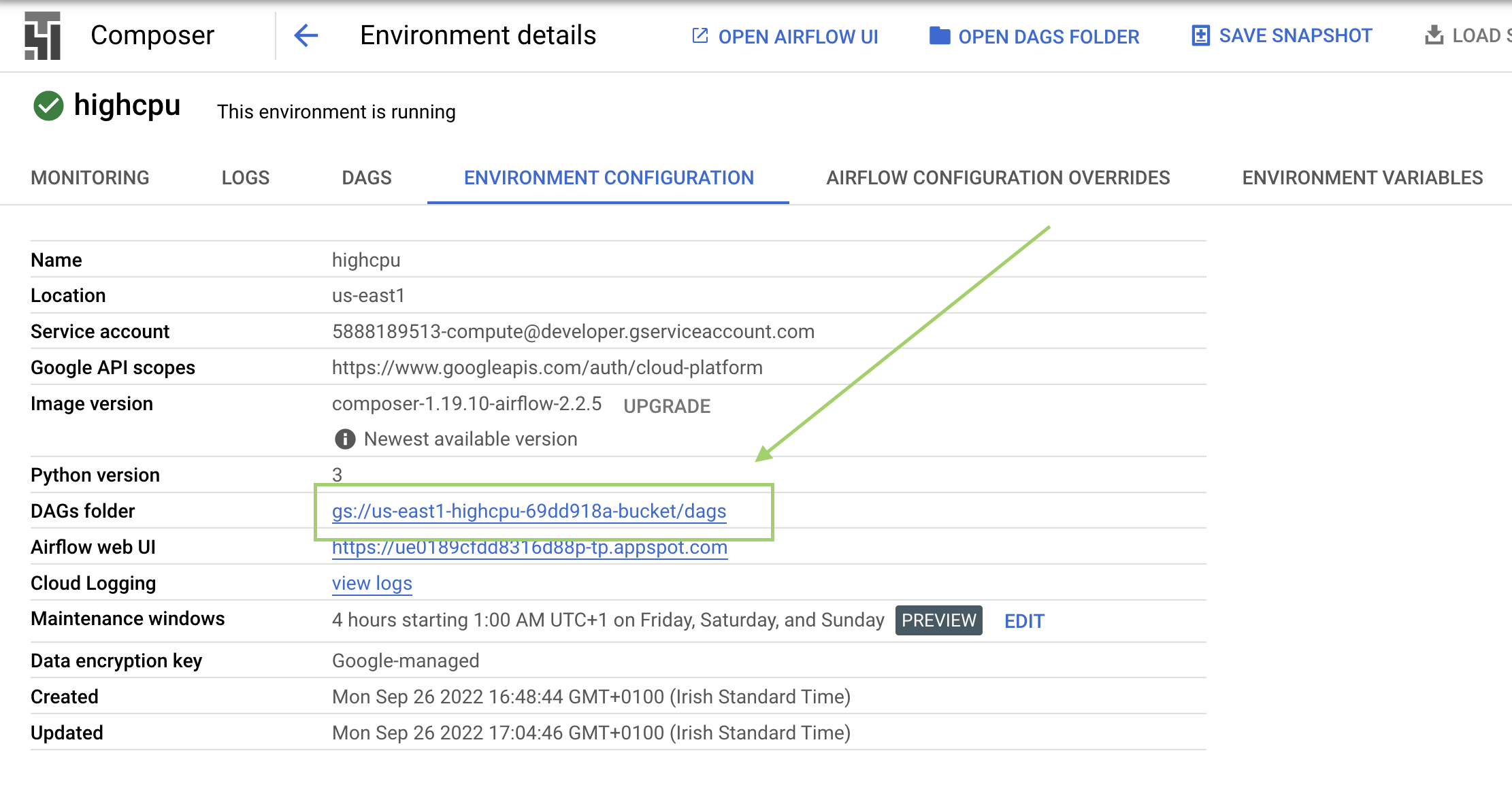
Cuando termine de crearse tu entorno, haz clic en el nombre (highcpu) para ver los detalles.
En Detalles del entorno, podrás ver información como la URL de la interfaz web de Airflow, el ID del clúster de Kubernetes Engine y un vínculo a la carpeta de los DAG, que está almacenada en tu bucket.
/dags.Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 5: Usa la IU de Airflow
Sigue estos pasos para acceder a la interfaz web de Airflow con la consola de Cloud:
- Regresa a la página Entornos.
- En la columna Webserver de Airflow del entorno, haz clic en Airflow.
- Haz clic en tus credenciales del lab.
- La interfaz web de Airflow se abrirá en una nueva ventana del navegador.
Tarea 6: Configura variables de Airflow
Las variables de Airflow son un concepto específico de Airflow que difiere de las variables de entorno.
-
Desde la barra de menú de Airflow, selecciona Admin > Variables y, luego, haz clic en + (Add a new record).
-
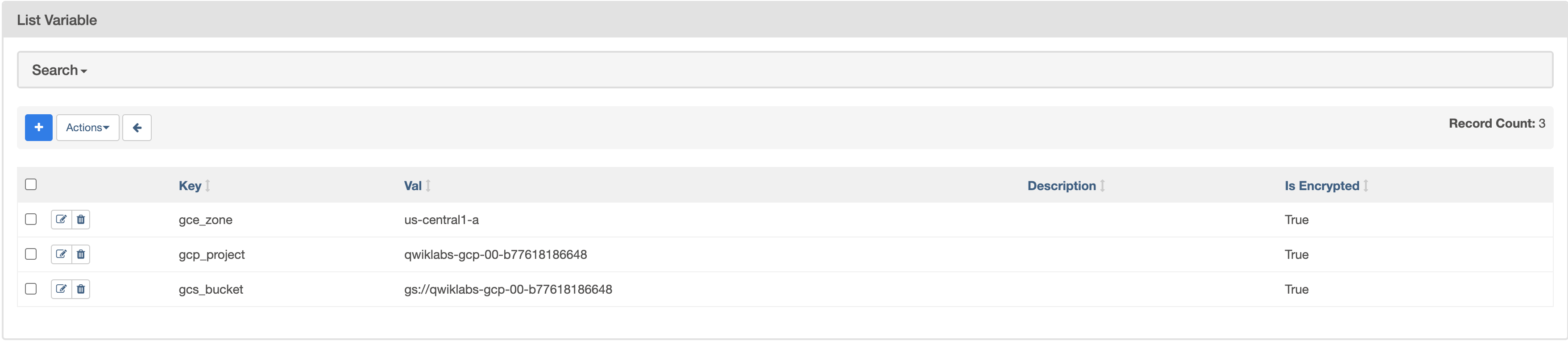
Crea las siguientes variables de Airflow:
gcp_project,gcs_bucketygce_zone:
|
CLAVE |
VALOR |
Detalles |
|
|
|
El proyecto de Google Cloud que usas para esta guía de inicio rápido. |
|
|
gs:// |
Este es el nombre del bucket de Cloud Storage que creaste anteriormente y que debería tener el mismo nombre que tu ID del proyecto, a menos que lo hayas cambiado. Este bucket almacena el resultado de los trabajos de Hadoop obtenidos de Dataproc. |
|
|
|
Esta es la zona de Compute Engine en la que se creará tu clúster de Cloud Dataproc. Para elegir una zona distinta, consulta Regiones y zonas disponibles. |
Cuando termines, la tabla de Variables debería verse de esta forma:
Tarea 7: Sube el DAG a Cloud Storage
Para subir el DAG, subirás una copia del archivo hadoop_tutorial.py al bucket de Cloud Storage que se creó automáticamente cuando creaste el entorno.
-
Para comprobarlo, dirígete a Composer > Entornos.
-
Haz clic en el entorno que creaste anteriormente para ir a sus detalles.
-
Haz clic en Configuración del entorno.
-
Busca la
carpeta de DAG, copia el valor para reemplazar<DAGs_folder_path>en el siguiente comando y ejecútalo en Cloud Shell:
Cloud Composer agrega el DAG a Airflow y lo programa automáticamente. Los cambios en el DAG tardan de 3 a 5 minutos. El flujo de trabajo ahora se denominará composer_hadoop_tutorial.
Podrás ver el estado de la tarea en la interfaz web de Airflow.
Haz clic en Revisar mi progreso para verificar el objetivo.
Explora las ejecuciones del DAG
Cuando subas tu archivo DAG a la carpeta dags en Cloud Storage, Cloud Composer analizará el archivo. Si no se encuentran errores, el nombre del flujo de trabajo aparecerá en la lista del DAG y el flujo de trabajo se pondrá en cola para ejecutarse de inmediato.
Asegúrate de estar en la pestaña DAGs, en la interfaz web de Airflow. Este proceso tardará varios minutos en completarse. Actualiza la página para asegurarte de ver la información más reciente.
-
En Airflow, haz clic en composer_hadoop_tutorial para abrir la página de detalles del DAG, que incluye una representación gráfica de las tareas del flujo de trabajo y las dependencias.
-
En la barra de herramientas, haz clic en Graph para cambiar a esa vista. Desplaza el mouse sobre el gráfico de cada tarea para ver su estado. Ten en cuenta que el borde de cada tarea también indica el estado (borde verde: running; rojo: failed; etcétera).
-
Si es necesario, activa la Auto refresh o haz clic en el ícono de actualizar para asegurarte de que estás consultando la información más reciente. Los bordes de los procesos cambian de color a medida que cambia su estado.
Si el color alrededor de create_dataproc_cluster cambió y el estado no es “running”, vuelve a ejecutar el flujo de trabajo desde la vista Graph. Si el estado es “running”, no debes realizar los 3 pasos que se indican a continuación.
- Haz clic en el gráfico create_dataproc_cluster.
- Haz clic en Clear para restablecer las tres tareas.
- Luego, haz clic en OK para confirmar.
Observa que cambió el color alrededor de create_dataproc_cluster y el estado es “running”.
También puedes supervisar el proceso en la consola de Cloud.
- Una vez que el estado de create_dataproc_cluster cambie a “running”, dirígete a Menú de navegación > Dataproc y, luego, haz clic en lo siguiente:
- Clústeres para supervisar la creación y eliminación de clústeres. El clúster que el flujo de trabajo creó es efímero: solo existe a la par del flujo de trabajo y se borra como parte de la última tarea de este.
- Trabajos para supervisar el trabajo de conteo de palabras de Apache Hadoop. Haz clic en el ID del trabajo para ver el resultado del registro de trabajos.
-
Cuando Dataproc alcance el estado “Running”, vuelve a Airflow y haz clic en Refresh para ver que el clúster esté completo.
-
Cuando el proceso
run_dataproc_hadoopesté completo, ve a Menú de navegación > Cloud Storage > Buckets y haz clic en el nombre de tu bucket para ver los resultados del conteo de palabras en la carpetawordcount.
Haz clic en Revisar mi progreso para verificar el objetivo.
Pon a prueba tus conocimientos
Para poner a prueba tus conocimientos sobre Google Cloud Platform, realiza nuestro cuestionario.
Borre el entorno de Cloud Composer
- Vuelva a la página de Entornos en Compositor.
- Seleccione la casilla junto a su entorno de Compositor.
- Haga clic en BORRAR.
- Confirme la ventana emergente haciendo clic en BORRAR otra vez.
¡Felicitaciones!
¡Felicitaciones! En este lab, creaste un entorno de Cloud Composer, subiste un DAG a Cloud Storage y ejecutaste un flujo de trabajo con el que se creó un clúster de Cloud Dataproc, se ejecutó un trabajo de conteo de palabras de Hadoop y se borró el clúster. También aprendiste sobre Airflow y los conceptos básicos, además de explorar la interfaz web de Airflow. Ahora puedes usar Cloud Composer para crear y administrar tus propios flujos de trabajo.
Próximos pasos
Este lab forma parte de una serie llamada Qwik Starts. Estos labs están diseñados para ofrecerte una visión general de las numerosas funciones disponibles de Google Cloud. Busca “Qwik Starts” en el catálogo de labs para elegir el próximo lab que desees completar.
- Para ver el valor de una variable, ejecuta el subcomando variables de la CLI de Airflow con el argumento get o usa la interfaz web de Airflow.
- Para obtener información sobre la interfaz web de Airflow, consulta Accede a la interfaz web de Airflow.
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 18 de diciembre de 2023
Prueba más reciente del lab: 18 de diciembre de 2023
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.