チェックポイント
Create Cloud Dataproc cluster
/ 50
Create a Logistic Regression Model
/ 50
Google Cloud Dataproc 上の Spark を使用した ML
GSP271

概要
はじめに
このラボでは、Apache Spark の ML ライブラリを使用してロジスティック回帰を実装します。Spark は Dataproc クラスタ上で実行し、多変数データセットのデータ用のモデルを作成します。
Dataproc は、Apache Spark と Apache Hadoop のクラスタを簡単かつコスト効率良く実行できる、高速で使いやすいフルマネージド クラウド サービスです。Dataproc は他の Google Cloud サービスと簡単に統合できるため、データ処理、分析、ML 用の高度で包括的なプラットフォームとして使用できます。
Apache Spark は、大規模なデータ処理のための分析エンジンです。Apache Spark の ML ライブラリである MLlib には、ロジスティック回帰がモジュールとして用意されています。Spark MLlib または Spark ML と呼ばれるこのライブラリには、標準的な ML アルゴリズムのほとんどの実装が含まれています(K 平均法クラスタリング、ランダム フォレスト、交互最小二乗法、ディシジョン ツリー、サポート ベクター マシンなど)。Spark は、Dataproc のような Hadoop クラスタで実行して非常に大きなデータセットを並列処理できます。
このラボで使用する基本データセットは US Bureau of Transport Statistics から取得します。データセットは米国の国内線フライトに関する履歴情報を提供し、データ サイエンスの多岐にわたるコンセプトと手法の実証に使用できます。このラボでは、このデータを CSV 形式のテキスト ファイルとして提供しています。
目標
- Spark を使用して ML 用のトレーニング データセットを作成する
- Spark を使用してロジスティック回帰の ML モデルを作成する
- Dataproc 上の Spark を使用して、ML モデルの予測動作を評価する
- モデルを評価する
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

タスク 1. Dataproc クラスタを作成する
通常、Hadoop ジョブを書く最初のステップは、Hadoop をインストールすることです。このステップは、クラスタを設定し、そこに Hadoop をインストールしてクラスタを構成することで、すべてのマシンがお互いを認識し、安全な方法で相互に通信できるようにすることを含みます。
その後、YARN と MapReduce のプロセスを開始し、ようやく Hadoop プログラムを書く準備が整います。Google Cloud 上において、Dataproc は MapReduce、Pig、Hive、Presto、Spark を実行可能な Hadoop クラスタをスピンアップするのに便利です。
Spark を使用している場合、Dataproc は Spark のフルマネージドで、サーバーレスな環境を提供します。つまり、Spark プログラムを送信するだけで、Dataproc が実行します。その点において、Apache Spark にとっての Dataproc は、Apache Beam にとっての Dataflow と同じです。実際、Dataproc と Dataflow はバックエンド サービスを共有しています。
このセクションでは、VM を作成し、その後 VM 上に Dataproc クラスタを作成します。
-
Cloud コンソールのナビゲーション メニュー(
)で、[Compute Engine] > [VM インスタンス] をクリックします。
-
startup-vmVM の横にある [SSH] ボタンをクリックし、ターミナルを起動して接続します。 -
[接続] をクリックして、SSH 接続を確認します。
-
次のコマンドを実行して、リポジトリ
data-science-on-gcpをクローニングし、ディレクトリ06_dataprocに移動します。
- 次のコードを使ってプロジェクトとバケット変数を設定します。
- ゾーンの依存関係をコード
--zone ${REGION}-aで削除することにより、create_cluster.shファイルを編集します。
出力は次のようになります。
-
Ctrl+X、Y、Enter の順にキーを押して、ファイルを保存します。
-
バケットの名前とバケットを配置するリージョンを指定して、ジョブを実行する Dataproc クラスタを作成します。
このコマンドは数分かかることがあります。
Dataproc 上の JupyterLab
-
Cloud コンソールのナビゲーション メニューで [Dataproc] をクリックします。場合によっては、[その他のプロダクト] をクリックして下にスクロールする必要があります。
-
クラスタのリストでクラスタの名前をクリックし、クラスタの詳細を表示します。
-
[ウェブ インターフェース] タブをクリックしてから、右側のペインの下部の [JupyterLab] をクリックします。
-
[ノートブック] ランチャー セクションで、[Python 3] をクリックして新しいノートブックを開きます。
ノートブックを使用するには、セルにコマンドを入力します。セル内のコマンドを実行するには、Shift + Enter キーを押すか、ノートブックの上部メニューにある三角形をクリックして [Run selected cells and advance] を選択します。
タスク 2. バケットを設定し、pyspark セッションを始める
- 未加工ファイルがホストされている Google Cloud Storage バケットを設定します。
- Shift + Enter キーを押すか、ノートブックの上部メニューにある三角形をクリックして [Run selected cells and advance] を選択し、セルを実行します。
- 次のコードブロックを使用して、Spark セッションを作成します。
このコードを Spark Python スクリプトの先頭に追加すると、インタラクティブな Spark シェルや Jupyter ノートブックを使用して作成したどんなコードでも、スタンドアロン スクリプトとして使用できるようになります。
トレーニング用の Spark DataFrame を作成する
- 新しいシェルに次のコマンドを入力します。
- セルを実行します。
タスク 3. データセットの読み取りとクリーンアップ
このラボの開始時には、自動スクリプトによってデータが CSV ファイルのセットとして用意され、Cloud Storage バケットの中に配置されます。
- 先ほど設定した環境変数から Cloud Storage バケットの名前を取得し、自動スクリプトにより Cloud Storage バケット内に用意された CSV を読み込むことで、
traindaysDataFrame を作成します。
この CSV では、トレーニング用に有効な日がサブセットとして識別されているため、flights データセット全体を、モデルのトレーニングに使用するデータセットとモデルのテストや検証に使用するデータセットに分割して、複数のビューを作成できます。
データセットの読み取り
- 新しいセル内に次のコマンドを入力して実行します。
- Spark SQL ビューを作成します。
- トレーニング データセット ビューの最初の数レコードをクエリします。
トレーニング テーブルの最初の 5 つのレコードが表示されます。

このプロセスの次の段階は、ソース データファイルの特定です。
- ここでは、ソース データファイルに
all_flights-00000-*シャード ファイルを使用します。その理由は、データセット全体を代表する典型的なデータのサブセットであることと、妥当な時間内に処理できることです。
#inputs = 'gs://{}/flights/tzcorr/all_flights-*'.format(BUCKET) # FULL
- 作成した入力ファイルから Spark SQL にデータを読み込みます。
- 次に、トレーニング データセットの一部として識別されている日のデータのみを使用するクエリを作成します。
- データの一部を調べて、問題がないか確認します。
「Truncated the string representation of a plan since it was too large(大きすぎるため、プランの文字列表現が切り捨てられます)」という警告が表示される場合があります。このラボでは無視しても問題ありません。この警告が該当するのは、SQL スキーマログを調べる場合だけです。出力は次のようになります。
- では、このデータセットを Spark で分析してみましょう。
出力は次のようになります。
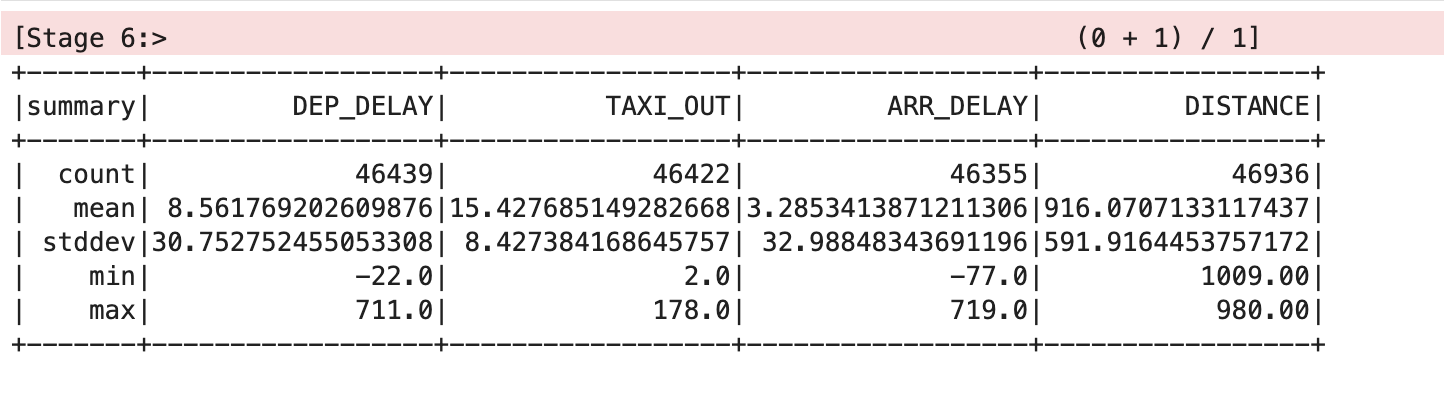
データセットを削除する
このテーブルでは、平均と標準偏差の値が見やすいように小数点以下第 2 位で丸められていますが、実際の画面には完全な浮動小数点値が表示されます。
このテーブルから、このデータには問題があることがわかります。DEP_DELAY、TAXI_OUT、ARR_DELAY、DISTANCE のカウント数が異なっており、変数の値が一部欠けているレコードが存在しています。これには次のような理由が考えられます。
- 予定されていたフライトが出発しなかった
- 出発したが離陸前にキャンセルされたフライトがある
- 行先変更されたために目的地に到着しなかったフライトがある
- 新しいセルに次のコードを入力します。
trainquery = """ SELECT DEP_DELAY, TAXI_OUT, ARR_DELAY, DISTANCE FROM flights f JOIN traindays t ON f.FL_DATE == t.FL_DATE WHERE t.is_train_day == 'True' AND f.dep_delay IS NOT NULL AND f.arr_delay IS NOT NULL """ traindata = spark.sql(trainquery) traindata.describe().show()
出力は次のようになります。
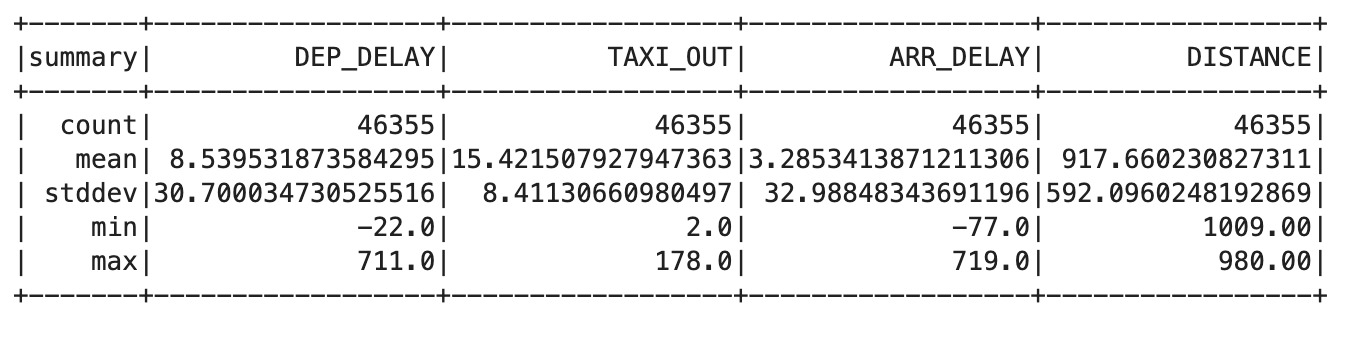
- 次のクエリを使用して、キャンセルされたフライトや行先変更されたフライトを削除します。
この出力が各列で同じカウント値になると、問題が解決したことを意味します。
タスク 4. ロジスティック回帰モデルを作成する
次に、上で作成した DataFrame 内のデータポイントのセットをトレーニング例に変換する関数を作成します。トレーニング例には、入力特徴のサンプルと、それらの入力に対する正解が含まれます。
この場合の正解は、到着遅延時間が 15 分未満かどうかです。入力に使用するラベルは、出発遅延時間、タクシーアウト時間、フライト距離の値です。
- 新しいセルに以下を入力して、実行し、トレーニング例関数の定義を作成します。
- 次に、このトレーニング例関数をトレーニング データセットにマッピングします。
- 以下のコマンドを入力して実行し、Spark ロジスティック回帰モジュール用のトレーニング DataFrame を入手します。
トレーニング DataFrame は、トレーニング データセットに基づいてロジスティック回帰モデルを作成します。
- すべての入力がゼロの場合に到着遅延の予測がゼロにならないため、
intercept=Trueパラメータを使用します。 - 使用するトレーニング データセットで、すべての入力がゼロの場合に予測がゼロになるべき場合は、
intercept=Falseを指定する必要があります。
- この train メソッドが終了すると、
lrmodelオブジェクトに重みと切片の値が含まれるようになります。これらの値を調べるには次のコマンドを使用します。
出力は次のようになります。
これらの重みを線形回帰の式で使用すると、任意の言語を使用したコードでモデルを作成できます。
- フライトに以下の入力変数を指定してこれをテストします。
- 6 分の出発遅延時間
- 12 分のタクシーアウト時間
- 594 マイルのフライト距離
1 という結果は、フライトが定刻通りに到着することを予測しています。
- では、出発遅延時間を大幅に増やして 36 分にするとどうなるでしょう。
0 の結果はフライトが定刻に到着しないことを意味します。
これらの結果は確率ではありません。デフォルトで 0.5 に設定されているしきい値に基づく真偽値です。
- 実際の確率を返すには、このしきい値を消去します。
結果は確率で、1 つ目の結果は 1 に近い値、2 つ目の結果は 0 に近い値になります。
- 定刻に到着する確率が 70% を下回った場合に会議をキャンセルできるように、しきい値を 0.7 に設定してみましょう。
今回も結果は 1 と 0 ですが、これらの結果に反映されている確率しきい値は、デフォルトの 50% ではなく 70% です。
タスク 5. ロジスティック回帰モデルを保存および復元する
Spark のロジスティック回帰モデルを直接 Cloud Storage に保存できます。これにより、モデルをゼロからトレーニングし直さなくても再利用できるようになります。
ストレージのロケーションには 1 つのモデルのみが含まれます。これにより、モデルの読み込みで問題を引き起こす他の既存ファイルの干渉を避けることができます。そのためには、Spark の回帰モデルを保存する前に、ストレージのロケーションが空であることを確認します。
- 新しいセルに次のコードを入力して、実行します。
モデルはまだ保存されていないため、「CommandException: 1 files/objects could not be removed」というエラーが返されるはずです。このエラーは、指定した場所にファイルが存在しないことを示します。これにより、モデルを保存する前にこの場所が空であることを確認できます。
- 次のコマンドを実行してモデルを保存します。
- 次に、メモリ内のモデル オブジェクトを破棄して、モデルデータが含まれなくなったことを確認します。
- 今度は、モデルをストレージから取得します。
モデル パラメータ(重みと切片の値)が復元されました。
タスク 6. ロジスティック回帰モデルで予測する
- 間違いなく定刻に到着しないシナリオでモデルをテストしてみましょう。
結果として 0 が出力されます。これは、このフライトの(70% の確率しきい値に基づいて)到着が遅延すると予測されたことを示しています。
- 最後に、定刻に到着するはずのデータを使用してモデルをもう一度テストしてみましょう。
結果として 1 が出力されます。これは、このフライトが(70% の確率しきい値に基づいて)定刻に到着すると予測されたことを示しています。
タスク 7. モデルの動作を調べる
- 次のコードを新しいセルに入力して、セルを実行します。
しきい値を取り除き、確率を得ます。到着が遅延する確率は、出発の遅延が大きくなるにつれて高くなります。
- 出発が 20 分遅延しタクシーアウト時間が 10 分の場合、フライトが定刻になる確率に距離がこのように影響します。
ご覧のように、影響は比較的小さいです。距離が非常な短距離から大陸横断飛行に変わるにつれて、確率は約 0.63 から約 0.76 に上昇します。
- 新しいセルで以下を実行します。
一方、タクシーアウト時間と距離を一定に保ち、出発遅延への依存性を調べると、より劇的な影響が見られます。
タスク 8. モデルを評価する
- ロジスティック回帰モデルを評価するには、テストデータが必要です。
- 次に、このトレーニング例関数をテスト用データセットにマッピングします。
- では、このデータセットを Spark で分析してみましょう。
出力は次のようになります。

-
eval関数を定義して、キャンセルの合計、ノンキャンセルの合計、正しいキャンセル、正しいノンキャンセルのフライトの詳細を返します。
- 次は、正しい予測ラベルを渡してモデルを評価します。
出力:
- 65% 超 75% 未満の判定しきい値に近い例だけを残します。
出力:
お疲れさまでした
ここでは、Dataproc クラスタでロジスティック回帰を行うための Spark を使用した方法を学びました。
次のラボを受講する
次のリンクで続行します。
次のステップと詳細情報
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 12 月 4 日
ラボの最終テスト日: 2023 年 12 月 4 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。