Checkpoints
Create Cloud Dataproc cluster
/ 50
Create a Logistic Regression Model
/ 50
Machine learning com o Spark no Google Cloud Dataproc
- GSP271
- Informações gerais
- Configuração e requisitos
- Tarefa 1. Criar um cluster do Dataproc
- Tarefa 2. Configurar o bucket e iniciar a sessão do pyspark
- Tarefa 3. Ler e limpar o conjunto de dados
- Tarefa 4. Desenvolver um modelo de regressão logística
- Tarefa 5. Salvar e restaurar um modelo de regressão logística
- Tarefa 6. Prever com o modelo de regressão logística
- Tarefa 7. Examinar o comportamento do modelo
- Tarefa 8. Avaliar o modelo
- Parabéns!
GSP271

Informações gerais
Introdução
Neste laboratório, você vai implementar regressão logística usando uma biblioteca de machine learning para Apache Spark. O Spark é executado em um cluster do Dataproc para desenvolver um modelo de dados de um conjunto de dados multivariável.
O Cloud Dataproc é um serviço de nuvem totalmente gerenciado, rápido e fácil de usar, que executa os clusters do Apache Spark e do Apache Hadoop de maneira simples e econômica. O Dataproc se integra facilmente a outros serviços do Google Cloud, oferecendo uma plataforma completa e potente de processamento de dados, análise e machine learning.
O Apache Spark é um mecanismo de análise para processamento de dados em grande escala. A regressão logística está disponível como um módulo da biblioteca de machine learning do Apache Spark, MLlib. O Spark MLlib, também chamado de Spark ML, inclui implementações para a maioria dos algoritmos de machine learning padrão, como clustering k-means, florestas aleatórias, mínimos quadrados alternados, árvores de decisão, máquinas de vetores de suporte e outros. O Spark pode ser executado em um cluster do Hadoop, como o Dataproc, para processar conjuntos de dados muito grandes em paralelo.
O conjunto de dados base que este laboratório usa foi obtido da Agência de Estatísticas de Transporte dos EUA. Ele tem informações históricas sobre voos domésticos nos Estados Unidos e pode ser usado para demonstrar muitos conceitos e técnicas da ciência de dados. Este laboratório fornece os dados como um conjunto de arquivos de texto formatados em CSV.
Objetivos
- Criar um conjunto de dados de treinamento para machine learning usando o Spark
- Desenvolver um modelo de machine learning de regressão logística usando o Spark
- Avaliar o comportamento preditivo de um modelo de machine learning usando o Spark no Dataproc
- Avaliar o modelo
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Tarefa 1. Criar um cluster do Dataproc
Normalmente, a primeira etapa para escrever jobs do Hadoop é iniciar a instalação do Hadoop. Isso envolve configurar um cluster, instalar o Hadoop nele e configurá-lo para que todas as máquinas conheçam umas às outras e possam se comunicar de maneira segura.
Em seguida, é necessário iniciar os processos YARN e MapReduce. Feito isso, você estará pronto para escrever alguns programas Hadoop. No Google Cloud, o Dataproc torna conveniente a criação de um cluster Hadoop capaz de executar MapReduce, Pig, Hive, Presto e Spark.
Se você estiver usando o Spark, o Dataproc vai oferecer um ambiente Spark totalmente gerenciado e sem servidor. Basta enviar um programa Spark para que ele seja executado pelo Dataproc. Dessa forma, o Dataproc está para o Apache Spark assim como o Dataflow está para o Apache Beam. Na verdade, o Dataproc e o Dataflow compartilham serviços de back-end.
Nesta seção, você vai criar uma VM e depois um cluster do Dataproc nela.
-
No console do Cloud, acesse o Menu de navegação (
) e clique em Compute Engine > Instâncias de VM.
-
Clique no botão SSH ao lado da VM
startup-vmpara iniciar um terminal e conectar. -
Clique em Conectar para confirmar a conexão SSH.
-
Execute o seguinte comando para clonar o repositório
data-science-on-gcpe navegue até o diretório06_dataproc:
- Defina a variável do projeto e do bucket usando o seguinte código:
- Edite o arquivo
create_cluster.shremovendo o código de dependência por zona--zone ${REGION}-a
Sua resposta será semelhante ao seguinte:
-
Salve o arquivo usando Ctrl+X, pressione Y e Enter
-
Crie um cluster do Dataproc para executar jobs, especificando o nome do bucket e a região em que ele está:
Esse comando pode levar alguns minutos.
JupyterLab no Dataproc
-
No console do Cloud, no Menu de navegação, clique em Dataproc. Talvez seja necessário clicar em Mais produtos e rolar a tela para baixo.
-
Na lista de Clusters, clique no nome do cluster para visualizar detalhes.
-
Clique na guia Interfaces da Web e depois em JupyterLab na parte de baixo do painel direito.
-
Na seção de acesso rápido Notebook, clique em Python 3 para abrir um novo notebook.
Para usar um Notebook, digite comandos em uma célula. Para executar os comandos na célula, pressione Shift + Enter ou clique no triângulo no menu superior "Notebook" para executar células selecionadas e avançar.
Tarefa 2. Configurar o bucket e iniciar a sessão do pyspark
- Configure um bucket do Google Cloud Storage onde seus arquivos brutos estão hospedados:
- Execute a célula pressionando Shift + Enter ou clicando no triângulo no menu superior do Notebook para Executar células selecionadas e avançar.
- Crie uma sessão Spark usando o seguinte bloco de código:
Quando esse código for adicionado ao início de qualquer script do Spark Python, todos os códigos desenvolvidos com o shell interativo do Spark ou o notebook do Jupyter também vão funcionar ao serem iniciados como scripts independentes.
Crie um DataFrame do Spark para treinamento
- Digite os seguintes comandos na nova célula:
- Execute a célula.
Tarefa 3. Ler e limpar o conjunto de dados
Quando você iniciou este laboratório, um script automatizado forneceu dados como um conjunto de arquivos CSV preparados e foi colocado no bucket do Cloud Storage.
- Agora, busque o nome do bucket do Cloud Storage na variável de ambiente definida anteriormente e crie o DataFrame
traindayslendo um CSV preparado que o script automatizado coloca em seu bucket do Cloud Storage.
O CSV identifica um subconjunto de dias como válido para treinamento. Isso permite que você crie visualizações de todo o conjunto de dados flights, que é dividido em um conjunto de dados usado para treinar seu modelo e um conjunto de dados usado para testar ou validar o modelo.
Ler o conjunto de dados
- Insira e execute os seguintes comandos na nova célula:
- Criar uma visualização Spark SQL:
- Consulte os primeiros registros da visualização do conjunto de dados de treinamento:
Isso mostra os cinco primeiros registros da tabela de treinamento:

A próxima etapa do processo é identificar os arquivos de dados de origem.
- Você usará o fragmento de arquivo
all_flights-00000-*para isso, porque ele tem um subconjunto representativo do conjunto de dados completo e seu processamento tem uma duração razoável:
#inputs = 'gs://{}/flights/tzcorr/all_flights-*'.format(BUCKET) # FULL
- Agora leia os dados no Spark SQL a partir do arquivo de entrada que você criou:
- Em seguida, crie uma consulta que use apenas os dados dos dias identificados como parte do conjunto de dados de treinamento:
- Inspecione alguns dados e verifique se estão corretos:
"Truncated the string representation of a plan since it was too large". Neste laboratório, você pode ignorar esse aviso porque ele só será relevante se você quiser inspecionar os logs do esquema SQL. O resultado deve ser algo semelhante ao seguinte:
- Peça ao Spark que faça uma análise do conjunto de dados:
Isso vai produzir algo semelhante ao seguinte:
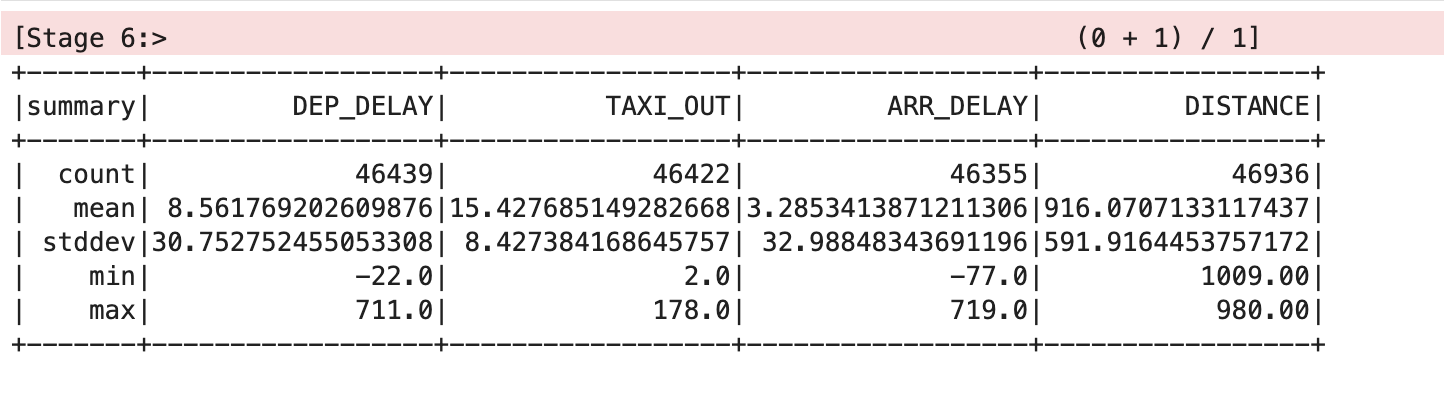
Limpar o conjunto de dados
Os valores de média e desvio padrão foram arredondados para duas casas decimais para tornar a tabela mais clara, mas os valores de ponto flutuante completos vão aparecer na tela.
A tabela mostra que há alguns problemas com os dados. Nem todos os registros têm valores para todas as variáveis. Há diferentes estatísticas de contagem para DEP_DELAY, TAXI_OUT, ARR_DELAY e DISTANCE. Isso acontece porque:
- há voos programados que não partem;
- alguns partem, mas são cancelados antes de decolar;
- alguns voos são desviados e, portanto, não chegam.
- Digite o seguinte código na nova célula:
trainquery = """ SELECT DEP_DELAY, TAXI_OUT, ARR_DELAY, DISTANCE FROM flights f JOIN traindays t ON f.FL_DATE == t.FL_DATE WHERE t.is_train_day == 'True' AND f.dep_delay IS NOT NULL AND f.arr_delay IS NOT NULL """ traindata = spark.sql(trainquery) traindata.describe().show()
Isso vai produzir algo semelhante ao seguinte:
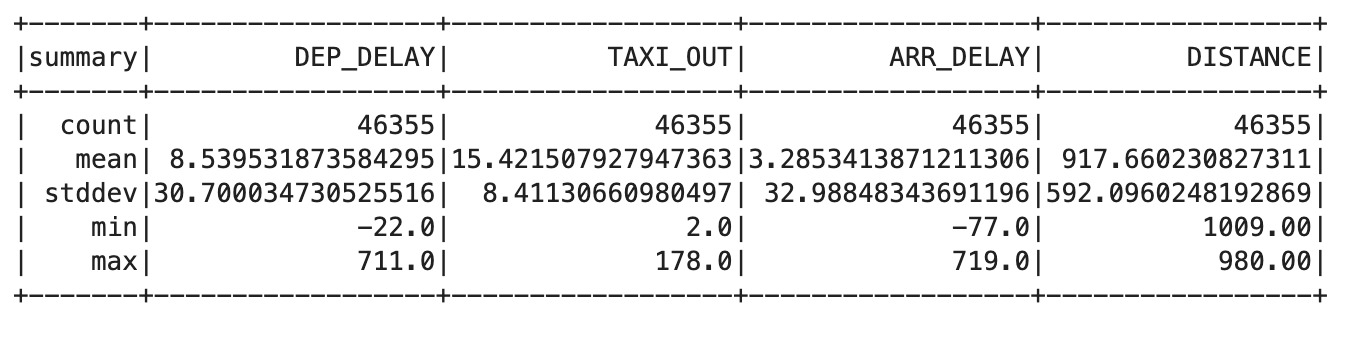
- Remova voos que foram cancelados ou desviados usando a seguinte consulta:
Essa saída deve mostrar o mesmo valor de contagem para cada coluna, o que indica que o problema foi corrigido.
Tarefa 4. Desenvolver um modelo de regressão logística
Agora você pode criar uma função que converta um conjunto de pontos de dados do seu DataFrame em um exemplo de treinamento. Um exemplo de treinamento contém uma amostra dos recursos de entrada e a resposta correta para essas entradas.
Neste caso, você responde se o atraso na chegada é inferior a 15 minutos. Os rótulos que você usa como entradas são os valores de atraso de partida, tempo de taxiamento antes da decolagem e distância do voo.
- Insira e execute o seguinte na nova célula para criar a definição para a função de exemplo de treinamento:
- Associe esta função de exemplo de treinamento ao conjunto de dados de treinamento:
- Insira e execute o seguinte comando para fornecer um DataFrame de treinamento para o módulo de regressão logística do Spark:
O DataFrame de treinamento cria um modelo de regressão logística com base em seu conjunto de dados de treinamento.
- Use o parâmetro
intercept=Trueporque a previsão do atraso de chegada não é igual a zero quando todas as entradas são zero neste caso. - Se estivesse trabalhando com um conjunto de dados de treinamento no qual você espera uma previsão de zero quando todas as entradas forem zero, nesse caso você especificaria
intercept=False.
- Quando esse método de treinamento terminar, o objeto
lrmodelterá pesos e um valor de interceptação que você poderá inspecionar:
A resposta será semelhante a:
Esses pesos, quando usados com a fórmula de regressão linear, permitem criar um modelo usando código na linguagem que você escolher.
- Teste isso fornecendo algumas variáveis de entrada para um voo que tenha:
- Atraso de partida de 6 minutos
- Tempo de taxiamento antes da decolagem de 12 minutos
- Distância de voo de 594 milhas
O resultado 1 prevê que o voo chegará no horário.
- Agora tente com um atraso de partida bem mais longo, de 36 minutos.
O resultado 0 prevê que o voo não chegará no horário.
Esses resultados não são probabilidades. Eles são retornados como verdadeiro ou falso com base em um limite configurado por padrão como 0,5.
- Você pode retornar a probabilidade real eliminando o limite:
Os resultados são probabilidades, com o primeiro próximo de 1 e o segundo próximo de 0.
- Defina o limite como 0,7 para corresponder à sua exigência de poder cancelar as reuniões se a probabilidade de uma chegada no horário cair para menos de 70%:
Seus resultados são novamente 1 e 0, mas agora elas refletem o limite de probabilidade de 70% que você exige, e não o padrão de 50%.
Tarefa 5. Salvar e restaurar um modelo de regressão logística
Você pode salvar um modelo de regressão logística do Spark diretamente no Cloud Storage. Isso permite reutilizar um modelo sem precisar treiná-lo novamente do zero.
Um local de armazenamento contém apenas um modelo. Isso evita interferência com outros arquivos que poderiam causar problemas de carregamento do modelo. Para fazer isso, verifique se o local de armazenamento está vazio antes de salvar seu modelo de regressão do Spark.
- Insira o seguinte código na nova célula e execute:
Isso vai retornar o erro CommandException: 1 files/objects could not be removed, porque o modelo ainda não foi salvo. O erro indica que não há arquivos presentes no local de destino. Você precisa ter certeza de que esse local está vazio antes de salvar o modelo, e esse comando garante isso.
- Salve o modelo executando o seguinte:
- Agora, destrua o objeto do modelo na memória e confirme que ele não contém mais nenhum dado do modelo:
- Agora recupere o modelo do armazenamento:
Os parâmetros do modelo, ou seja, os pesos e os valores do intercepto, foram restaurados.
Tarefa 6. Prever com o modelo de regressão logística
- Teste o modelo com um cenário em que o voo definitivamente não chegará no horário:
Isso imprime 0, prevendo que o voo provavelmente vai chegar atrasado, dado seu limite de probabilidade de 70%.
- Por fim, volte a testar o modelo usando dados de um voo que deve chegar no horário:
Isso imprime 1, prevendo que o voo provavelmente vai chegar a tempo, dado seu limite de probabilidade de 70%.
Tarefa 7. Examinar o comportamento do modelo
- Insira o seguinte código em uma nova célula e execute a célula:
Com os limites removidos, você obtém probabilidades. A probabilidade de chegar atrasado aumenta à medida que cresce o atraso na partida.
- Com um atraso na partida de 20 minutos e um tempo de taxiamento antes de decolar de 10 minutos, a distância afeta a probabilidade de o voo chegar no horário da seguinte maneira:
Você pode notar que o efeito é relativamente pequeno. A probabilidade aumenta de cerca de 0,63 para cerca de 0,76 à medida que a distância muda de um trecho muito curto para um voo intercontinental.
- Execute o seguinte na nova célula:
Por outro lado, se mantivermos a distância e o tempo de taxiamento antes de decolar constantes e examinarmos a dependência do atraso na partida, teremos um impacto mais significativo.
Tarefa 8. Avaliar o modelo
- Para avaliar o modelo de regressão logística, você precisa de dados de teste:
- Agora associe esta função de exemplo de treinamento ao conjunto de dados de teste:
- Peça ao Spark que faça uma análise do conjunto de dados:
Isso vai produzir algo semelhante ao seguinte:

- Defina uma função
evale retorne detalhes de total de cancelamentos, total de não cancelamentos, cancelamentos corretos e não cancelamentos corretos de voos:
- Agora, avalie o modelo passando o rótulo previsão correta:
Saída:
- Mantenha apenas os exemplos próximos ao limite de decisão superior a 65% e inferior a 75%:
Saída:
Parabéns!
Agora você sabe usar o Spark para realizar regressão logística com um cluster do Dataproc.
Comece o próximo laboratório
Continue com:
Próximas etapas / Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 4 de dezembro de 2023
Laboratório testado em 4 de dezembro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.