체크포인트
Create a new dataset and table to store the data
/ 20
Execute the query to see how many unique products were viewed
/ 15
Execute the query to use the UNNEST() on array field
/ 15
Create a dataset and a table to ingest JSON data
/ 20
Execute the query to COUNT how many racers were there in total
/ 10
Execute the query that will list the total race time for racers whose names begin with R
/ 10
Execute the query to see which runner ran fastest lap time
/ 10
BigQuery에서 JSON, 배열 및 구조체 작업 수행하기
GSP416

개요
BigQuery는 Google의 완전 관리형, 노옵스(NoOps), 저비용 분석 데이터베이스입니다. BigQuery를 사용하면 관리할 인프라나 데이터베이스 관리자가 없어도 테라바이트 단위의 데이터를 쿼리할 수 있습니다. BigQuery는 SQL을 사용하므로 종량제 모델의 장점을 활용할 수 있습니다. BigQuery를 사용하면 데이터를 분석하여 의미 있고 유용한 정보를 찾는 데 집중할 수 있습니다.
이 실습에서는 BigQuery 내 반정형 데이터 작업(JSON, 배열 데이터 유형 수집)을 심도 있게 다룹니다. 중첩 및 반복되는 필드를 포함하는 단일 테이블로 스키마를 비정규화하면 성능이 개선될 수는 있지만 배열 데이터 작업을 위한 SQL 문법이 복잡해질 수 있습니다. 다양한 반정형 데이터 세트의 로드, 쿼리, 문제 해결, 중첩 해제를 연습합니다.
설정
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머에는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지 표시됩니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
- 실습을 완료하기에 충분한 시간---실습을 시작하고 나면 일시중지할 수 없습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다. 왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 패널이 있습니다.
- Google 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google 콘솔 열기를 클릭합니다. 실습에서 리소스가 가동된 후 로그인 페이지가 표시된 다른 탭이 열립니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다. -
필요한 경우 실습 세부정보 패널에서 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다. 다음을 클릭합니다.
-
실습 세부정보 패널에서 비밀번호를 복사하여 시작 대화상자에 붙여넣습니다. 다음을 클릭합니다.
중요: 왼쪽 패널에 표시된 사용자 인증 정보를 사용해야 합니다. Google Cloud Skills Boost 사용자 인증 정보를 사용하지 마세요. 참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다. -
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의합니다.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 않습니다.
- 무료 평가판을 신청하지 않습니다.
잠시 후 Cloud 콘솔이 이 탭에서 열립니다.

BigQuery 콘솔 열기
- Google Cloud 콘솔에서 탐색 메뉴 > BigQuery를 선택합니다.
Cloud 콘솔의 BigQuery에 오신 것을 환영합니다라는 메시지 상자가 열립니다. 이 메시지 상자에서는 빠른 시작 가이드 및 출시 노트로 연결되는 링크가 제공됩니다.
- 완료를 클릭합니다.
BigQuery 콘솔이 열립니다.
작업 1. 테이블을 저장할 새 데이터 세트 만들기
- BigQuery에서 프로젝트 ID 옆에 있는 점 3개를 클릭하고 데이터 세트 만들기를 클릭합니다.
-
새 데이터 세트 이름을
fruit_store로 지정합니다. 다른 옵션(데이터 위치, 기본 만료 시간)은 기본값으로 유지합니다. -
데이터 세트 만들기를 클릭합니다.
작업 2. SQL에서 배열 다루기 연습
일반적으로 SQL에서는 아래에 나와 있는 과일 목록처럼 각 행에 하나의 값만 있습니다.
|
행 |
과일 |
|
1 |
raspberry |
|
2 |
blackberry |
|
3 |
strawberry |
|
4 |
cherry |
매장에 있는 각 사람에 대한 과일 항목 목록이 필요하다면 어떻게 해야 할까요? 다음과 같이 표시할 수 있습니다.
|
행 |
과일 |
사람 |
|
1 |
raspberry |
sally |
|
2 |
blackberry |
sally |
|
3 |
strawberry |
sally |
|
4 |
cherry |
sally |
|
5 |
orange |
frederick |
|
6 |
apple |
frederick |
기존의 관계형 데이터베이스 SQL에서는 반복되는 이름을 보면 즉시 위와 같은 테이블을 두 개의 개별 테이블, 즉 '과일 항목'과 '사람'으로 분할해야겠다고 생각할 것입니다. 이 프로세스를 정규화(단일 테이블에서 다수의 테이블로 변환)라고 합니다. 이는 mySQL과 같은 트랜잭션 데이터베이스에서 일반적으로 활용하는 방법입니다.
데이터 웨어하우징의 경우에는 데이터 분석가가 이와 반대로 진행(비정규화)하고 많은 개별 테이블을 하나의 대형 보고 테이블로 변환합니다.
이제 반복되는 필드를 사용하여 단일 테이블에서 다양한 세분화 수준으로 데이터를 저장하는 다른 방법을 알아보겠습니다.
|
행 |
과일(배열) |
사람 |
|
1 |
raspberry |
sally |
|
blackberry | ||
|
strawberry | ||
|
cherry | ||
|
2 |
orange |
frederick |
|
apple |
이 테이블의 이상한 점은 무엇인가요?
- 행이 2개뿐입니다.
- 단일 행에 과일에 대한 다양한 필드 값이 있습니다.
- 사람이 모든 필드 값과 연결되어 있습니다.
핵심은 무엇일까요? 바로 array 데이터 유형이라는 것입니다.
과일 배열을 더 쉽게 해석해 보면 다음과 같습니다.
|
행 |
과일(배열) |
사람 |
|
1 |
[raspberry, blackberry, strawberry, cherry] |
sally |
|
2 |
[orange, apple] |
frederick |
이 두 테이블은 동일한 테이블입니다. 여기에서 배울 수 있는 두 가지 요점은 다음과 같습니다.
- 배열은 단순히 각괄호([ ]) 안에 나열된 항목입니다.
- BigQuery는 시각적으로 평면화된 형태로 배열을 표시합니다. 단순히 배열의 값을 수직으로 나열합니다(모든 값은 여전히 단일 행에 속함).
직접 해 보세요.
- BigQuery 쿼리 편집기에 다음을 입력합니다.
-
실행을 클릭합니다.
-
이제 다음을 실행해 봅니다.
다음과 같은 오류가 반환될 것입니다.
오류: Array elements of types {INT64, STRING} do not have a common supertype at [3:1]
배열은 한 가지 데이터 유형(전부 문자열, 전부 숫자)만 사용할 수 있습니다.
- 쿼리할 최종 테이블은 다음과 같습니다.
-
실행을 클릭합니다.
-
결과를 보고 JSON 탭을 클릭하여 결과의 중첩된 구조를 확인합니다.
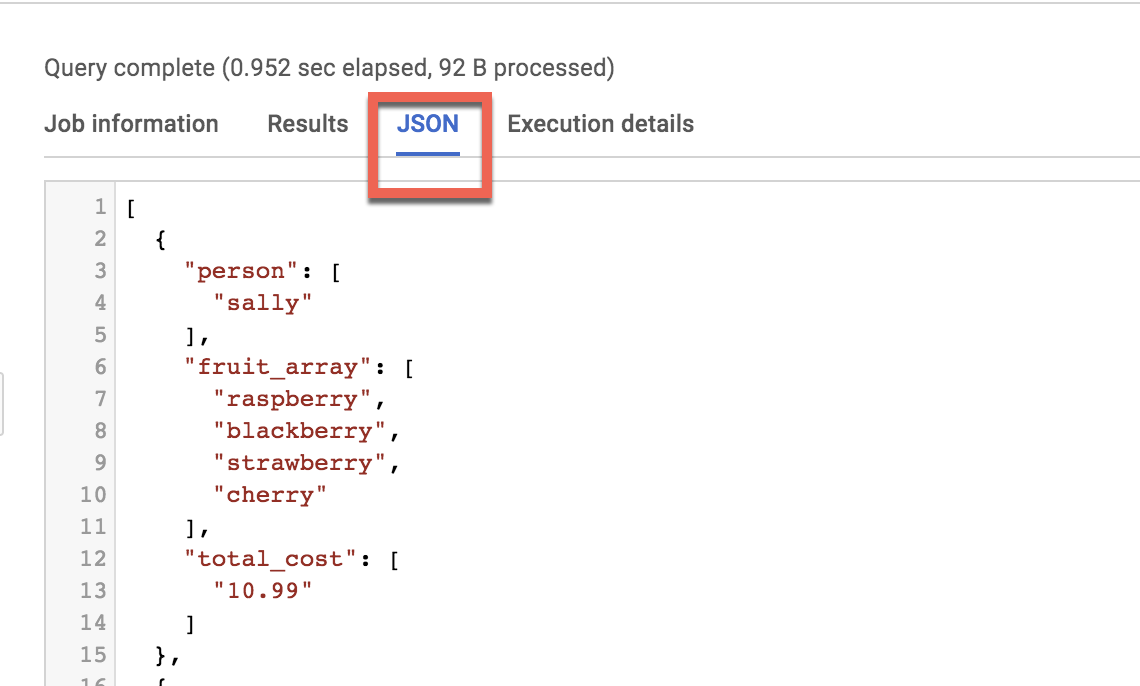
반정형 JSON을 BigQuery로 로드하기
BigQuery로 수집해야 하는 JSON 파일이 있다면 어떻게 해야 할까요?
데이터 세트에서 새로 fruit_details 테이블을 만듭니다.
-
fruit_store데이터 세트를 클릭합니다.
테이블 만들기 옵션이 표시됩니다.
- 테이블에 다음 세부정보를 추가합니다.
- 소스: 테이블을 만들 소스 드롭다운에서 Google Cloud Storage를 선택합니다.
-
Cloud Storage 버킷에서 파일 선택:
data-insights-course/labs/optimizing-for-performance/shopping_cart.json - 파일 형식: JSONL(줄바꿈으로 구분된 JSON)
-
새 테이블 이름을
fruit_details로 정합니다. -
스키마(자동 감지) 체크박스를 선택합니다.
-
테이블 만들기를 클릭합니다.
스키마에서 fruit_array는 REPEATED로 표시되며 이는 배열이라는 뜻입니다.
요약
- BigQuery는 기본적으로 배열을 지원합니다.
- 배열 값의 데이터 유형은 동일해야 합니다.
- 배열은 BigQuery에서 REPEATED(반복) 필드라고 합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 3. ARRAY_AGG()로 나만의 배열 만들기
아직 테이블에 배열이 없다면 배열을 만들어 보세요.
- 아래 쿼리를 복사하여 붙여넣기하고 해당 공개 데이터 세트를 살펴보세요.
- 실행을 클릭한 후 결과를 확인합니다.
이제 ARRAY_AGG() 함수를 사용하여 문자열 값을 배열로 집계합니다.
- 아래 쿼리를 복사하여 붙여넣기하고 해당 공개 데이터 세트를 살펴보세요.
- 실행을 클릭한 후 결과를 확인합니다.
- 다음으로
ARRAY_LENGTH()함수를 사용하여 조회된 페이지 및 제품 수를 계산합니다.
- 이제
ARRAY_AGG()에DISTINCT를 추가하여 중복된 페이지와 제품을 삭제하고 조회된 고유 제품 수를 확인합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
요약
배열로 다음과 같은 유용한 작업을 수행할 수 있습니다.
-
ARRAY_LENGTH(<array>)로 요소 수 찾기 -
ARRAY_AGG(DISTINCT <field>)로 중복된 요소 삭제 -
ARRAY_AGG(<field> ORDER BY <field>)로 요소 정렬 -
ARRAY_AGG(<field> LIMIT 5)로 제한
작업 4. 이미 배열이 있는 데이터 세트 쿼리하기
Google 애널리틱스의 BigQuery 공개 데이터 세트 bigquery-public-data.google_analytics_sample에는 본 과정의 데이터 세트 data-to-insights.ecommerce.all_sessions보다 필드와 행이 더 많습니다. 게다가 기본적으로 제품, 페이지, 거래와 같은 필드 값이 ARRAY로 저장되어 있습니다.
- 아래 쿼리를 복사하여 붙여넣기하고 사용 가능한 데이터를 살펴보고 반복되는 값이 있는 필드(배열)를 찾을 수 있는지 확인해 보세요.
-
쿼리를 실행합니다.
-
결과에서 오른쪽으로 스크롤하여
hits.product.v2ProductName필드로 이동합니다(여러 필드 별칭은 곧 설명해 드리겠습니다).
Google 애널리틱스 스키마에서 제공되는 필드 수는 분석하기에는 많을 수 있습니다.
- 이전과 같이 방문 및 페이지 이름 필드만 쿼리해 보겠습니다.
다음과 같은 오류가 발생합니다.
오류:Cannot access field page on a value with type ARRAY<STRUCT<hitNumber INT64, time INT64, hour INT64, ...>> at [3:8]
일반적으로 REPEATED 필드(배열)를 쿼리하려면 먼저 배열을 다시 행으로 나누어야 합니다.
예를 들어 hits.page.pageTitle의 배열이 현재 다음과 같이 단일 행으로 저장되어 있습니다.
그리고 다음과 같이 되어야 합니다.
SQL로는 어떻게 하면 될까요?
정답: 다음과 같이 배열 필드에 UNNEST() 함수를 사용합니다.
나중에 UNNEST() 함수를 좀 더 자세하게 설명하겠지만 지금은 다음 사항만 기억하세요.
- 배열 요소를 다시 행으로 돌리려면 배열에 UNNEST() 함수를 수행해야 합니다.
- UNNEST() 함수는 FROM 절에 있는 테이블 이름 뒤에 옵니다(사전 조인된 테이블이라는 개념으로 생각하세요).
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 5. STRUCT 소개
필드 별칭 hit.page.pageTitle이 마침표로 구분된 3개의 필드처럼 보이는 이유가 궁금하셨을 것입니다. ARRAY 값을 사용하면 필드 단위로 깊이 있게 분석할 수 있는 것처럼, 관련 필드를 그룹화하여 스키마에서 폭넓게 분석할 수 있는 데이터 유형도 있습니다. 해당 SQL 데이터 유형은 STRUCT 데이터 유형입니다.
STRUCT의 개념을 이해하는 가장 쉬운 방법은 기본 테이블에 개별 테이블이 사전에 조인되어 있다고 생각하는 것입니다.
STRUCT에는 다음 항목이 있을 수 있습니다.
- 단일 또는 다수 필드
- 필드별로 동일하거나 다른 데이터 유형
- 고유 별칭
테이블과 비슷한 것 같나요?
STRUCT가 포함된 데이터 세트 탐색
-
bigquery-public-data 데이터 세트를 열려면 +추가를 클릭한 후 이름별로 프로젝트에 별표표시를 선택하고
bigquery-public-data라는 이름을 입력합니다. -
별표를 클릭합니다.
탐색기 섹션에 bigquery-public-data 프로젝트가 표시됩니다.
-
bigquery-public-data를 엽니다.
-
google_analytics_sample 데이터 세트를 찾아 엽니다.
-
ga_sessions(366)_ 테이블을 클릭합니다.
-
스키마를 스크롤하면서 브라우저의 찾기 기능을 사용하여 다음 질문에 답변합니다.
예상대로 최신 전자상거래 웹사이트에는 엄청난 양의 웹사이트 세션 데이터가 저장되어 있습니다.
단일 테이블에 STRUCT가 32개 있을 때의 주요 이점은 JOIN을 수행하지 않고도 다음과 같은 쿼리를 수행할 수 있다는 것입니다.
.* 문법은 BigQuery가 해당 STRUCT의 모든 필드를 반환하도록 지정합니다(totals.*가 마치 조인 대상인 별도의 테이블인 것처럼 작업 수행).대형 보고 테이블을 STRUCT(사전 조인된 '테이블') 및 ARRAY(심층 세분화)로 저장하면 다음을 수행할 수 있습니다.
- 32개의 테이블 JOIN을 방지하여 상당한 성능상 이점 확보
- 필요하면 ARRAY에서 세분화된 데이터를 가져올 수 있지만 가져오지 않더라도 부정적인 영향을 받지 않음(BigQuery가 디스크에 각 열을 개별적으로 저장함)
- JOIN 키를 신경쓰거나 필요한 데이터가 어느 테이블에 있는지 고민하는 대신 단일 테이블에 모든 비즈니스 컨텍스트 보유
작업 6. STRUCT 및 배열 연습
다음 데이터 세트는 트랙을 도는 주자들의 랩 타입입니다. 각 랩은 '스플릿'이라고 지칭합니다.

- 다음 쿼리를 통해 STRUCT 문법을 실행해 보고 구조체 컨테이너 내에 있는 다양한 필드 유형을 확인해 보세요.
|
행 |
runner.name |
runner.split |
|
1 |
Rudisha |
23.4 |
필드 별칭과 관련해 무엇을 파악하셨나요? 구조체 내에 중첩된 필드(이름 및 스플릿은 주자의 하위 집합)가 있으므로 점 표기법으로 표시됩니다.
단일 경주에서 한 주자의 스플릿 타임(랩당 시간)이 여러 개라면 어떻게 해야 할까요?
배열을 사용하면 됩니다.
- 아래 쿼리를 실행하여 다음과 같은 결과가 나오는지 확인해 보세요.
|
행 |
runner.name |
runner.splits |
|
1 |
Rudisha |
23.4 |
|
26.3 | ||
|
26.4 | ||
|
26.1 |
요약하면 다음과 같습니다.
- 구조체는 여러 필드 이름과 데이터 유형이 내부에 중첩되어 있는 컨테이너입니다.
- 배열은 구조체 내에 있는 필드 유형 중 하나일 수 있습니다(예: 위에 있는 스플릿 필드)
JSON 데이터 수집하기 연습
-
racing이라는 제목의 새로운 데이터 세트를 만듭니다. -
racing데이터 세트를 클릭하고 '테이블 만들기'를 클릭합니다.
- 소스: 테이블을 만들 소스 드롭다운에서 Google Cloud Storage를 선택합니다.
-
Cloud Storage 버킷에서 파일 선택:
data-insights-course/labs/optimizing-for-performance/race_results.json - 파일 형식: JSONL(줄바꿈으로 구분된 JSON)
- 스키마에서 텍스트로 편집 슬라이더를 클릭하여 다음을 추가합니다.
-
새로운
race_results테이블을 호출합니다. -
테이블 만들기를 클릭합니다.
-
로드가 완료되면 새로 만든 테이블의 스키마를 미리보기합니다.
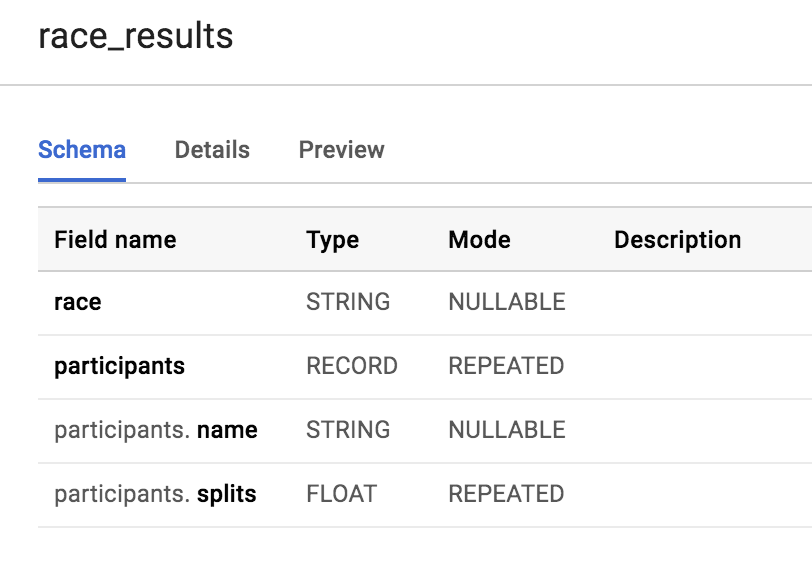
어느 필드가 STRUCT인가요? 어떻게 아셨나요?
RECORD 유형이므로 participants 필드가 STRUCT입니다.
어느 필드가 ARRAY인가요?
participants.splits 필드가 상위 participants 구조체 내부에 있는 float 배열입니다. 이 필드의 모드는 배열을 나타내는 REPEATED입니다. 단일 필드 내에 여러 값이 있으므로 해당 배열의 값은 중첩된 값이라고 합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
중첩되고 반복되는 필드 쿼리하기 연습
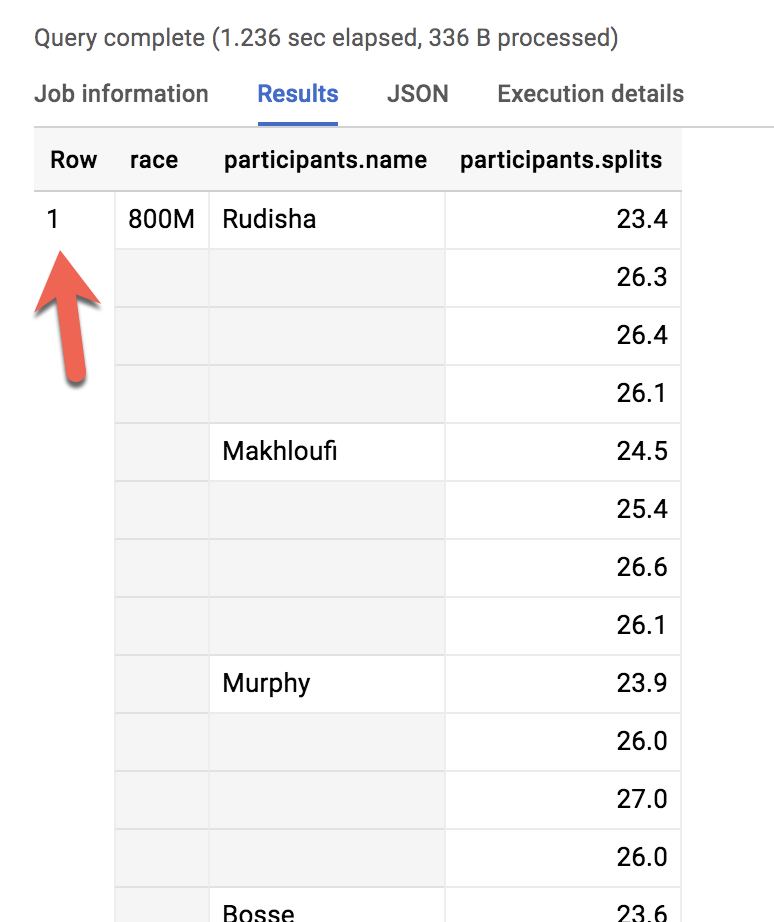
- 800미터 경주의 모든 주자를 살펴보겠습니다.
몇 개의 행이 반환되었나요?
정답: 1
각 주자 이름 및 경주 유형을 나열하려면 어떻게 해야 하나요?
- 아래 스키마를 실행하고 결과를 확인해 보세요.
오류: Cannot access field name on a value with type ARRAY<STRUCT<name STRING, splits ARRAY<FLOAT64>>>> at [2:27]
집계 함수를 사용할 때 GROUP BY를 사용하는 것을 깜빡한 것과 마찬가지로, 여기서는 2개의 다른 세분화 수준이 있습니다. 경주의 행은 1개이고 참가자 이름의 행은 3개입니다. 그렇다면 다음과 같은 형태를...
|
행 |
race |
participants.name |
|
1 |
800M |
Rudisha |
|
2 |
??? |
Makhloufi |
|
3 |
??? |
Murphy |
다음과 같이 바꾸려면 어떻게 해야 할까요?
|
행 |
race |
participants.name |
|
1 |
800M |
Rudisha |
|
2 |
800M |
Makhloufi |
|
3 |
800M |
Murphy |
기존의 관계형 SQL에서는 경주 테이블과 참가자 테이블이 있는 경우 두 테이블에서 정보를 얻기 위해 무엇을 수행해야 했나요? 둘을 JOIN했을 것입니다. 여기서 참가자 STRUCT(개념적으로 테이블과 매우 유사함)는 이미 경주에 속해 있지만 STRUCT가 아닌 필드 'race'와의 상관관계가 아직 올바르게 규정되지는 않았습니다.
800M 경주와 첫 번째 테이블의 각 주자의 상관관계를 보여주기 위해 사용할 SQL 명령어 두 단어는 무엇인가요?
정답: CROSS JOIN
좋습니다.
- 이제 다음을 실행해 보겠습니다.
Table name "participants" missing dataset while no default dataset is set in the request.
참가자 STRUCT가 테이블과 유사하더라도 엄밀히 말하자면 여전히 racing.race_results 테이블의 필드입니다.
- 다음과 같이 쿼리에 데이터 세트 이름을 추가하세요.
- 그리고 실행을 클릭합니다.
잘하셨습니다. 각 경주별로 모든 주자를 나열했습니다.
|
행 |
race |
name |
|
1 |
800M |
Rudisha |
|
2 |
800M |
Makhloufi |
|
3 |
800M |
Murphy |
|
4 |
800M |
Bosse |
|
5 |
800M |
Rotich |
|
6 |
800M |
Lewandowski |
|
7 |
800M |
Kipketer |
|
8 |
800M |
Berian |
- 다음을 통해 마지막 쿼리를 단순화할 수 있습니다.
- 원래 테이블에 별칭 추가
- 'CROSS JOIN'이라는 단어를 쉼표로 바꾸기(쉼표가 암시적으로 교차 조인을 수행)
이렇게 하면 동일한 쿼리 결과가 표시됩니다.
경주 유형이 하나 이상인 경우(800M, 100M, 200M) CROSS JOIN은 카티전 프로덕트처럼 모든 주자의 이름을 가능한 모든 경주에 연결하지 않을까요?
정답: 아닙니다. 이 교차 조인은 단일 행과 연결된 요소만 압축해제하는 상관 교차 조인입니다. 자세한 설명은 ARRAY 및 STRUCT 다루기를 참조하세요.
STRUCT 요약:
- SQL STRUCT는 단순히 다양한 데이터 유형으로 이루어진 서로 다른 데이터 필드의 컨테이너입니다. 구조체(Struct)란 말은 데이터 구조를 뜻합니다. 앞서 살펴본 예시를 떠올려 보세요.
STRUCT(``"Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits``)`` AS runner - STRUCT는 별칭(예: 위에 나와 있는 주자)이 주어지고 개념적으로 기본 테이블 내부에 있는 테이블로 생각할 수 있습니다.
- 요소에 작업을 수행하려면 STRUCT(및 ARRAY)는 압축해제되어야 합니다. 구조체를 압축해제하여 평면화하기 위해 구조체 자체의 이름 또는 배열인 구조체 필드를 UNNEST()로 래핑합니다.
작업 7. 실습 문제: STRUCT()
앞선 만든 racing.race_results 테이블을 사용하여 아래 질문에 답변해 보세요.
과제: 쿼리를 작성하여 전체 주자 수를 COUNT하세요.
- 일부만 작성된 아래의 쿼리를 사용하여 시작합니다.
FROM 이후에 추가 데이터 소스로 구조체 이름을 교차 조인해야 합니다.가능한 해결책:
|
행 |
racer_count |
|
1 |
8 |
정답: 경주에 참가한 주자는 8명입니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 8. 실습 문제: UNNEST( )로 배열 압축해제
이름이 R로 시작하는 주자의 총 경주 시간을 나열하는 쿼리를 작성해 봅니다. 전체 시간이 빠른 순서대로 결과를 정렬하세요. UNNEST() 연산자를 사용하고 일부만 작성된 다음 쿼리를 사용해 시작합니다.
- 다음 쿼리를 완성하세요.
- FROM 절 이후에 구조체와 구조체 내의 배열을 데이터 소스로 압축해제해야 합니다.
- 해당하는 경우에 별칭을 사용해야 합니다.
가능한 해결책:
|
행 |
name |
total_race_time |
|
1 |
Rudisha |
102.19999999999999 |
|
2 |
Rotich |
103.6 |
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 9. 배열 값 내에서 필터링
800미터 경주에서 기록된 가장 빠른 랩 시간이 23.2초인 것을 확인했지만 해당 랩을 뛴 주자를 확인하지는 못했습니다. 해당 결과를 반환하는 쿼리를 만들어 보세요.
- 일부만 작성된 다음 쿼리를 완성하세요.
가능한 해결책:
|
행 |
name |
split_time |
|
1 |
Kipketer |
23.2 |
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
수고하셨습니다.
지금까지 유용한 정보를 얻기 위해 JSON 데이터 세트를 수집하고, ARRAY 및 STRUCT를 만들고, 반정형 데이터의 중첩을 해제해 보았습니다.
퀘스트 완료
이 사용자 주도형 실습은 BigQuery for Data Warehousing 퀘스트의 일부입니다. 퀘스트는 연관성이 있는 여러 실습을 하나의 학습 과정으로 구성한 것입니다. 이 퀘스트를 완료하면 위의 배지를 얻고 수료를 인증할 수 있습니다. 배지를 공개하고 온라인 이력서 또는 소셜 미디어 계정에 연결할 수 있습니다. 이 실습을 완료했다면 퀘스트에 등록하여 즉시 수료 크레딧을 받으세요. 다른 퀘스트도 확인하기
다음 실습 참여하기
BigQuery에서 날짜로 파티션을 나눈 테이블 만들기 실습에 참여하여 퀘스트를 계속 진행하거나 다음 추천 항목을 확인해 보세요.
다음 단계/자세히 알아보기
- 추가 자료는 배열 작업하기를 참조하세요.
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2023년 8월 25일
실습 최종 테스트: 2023년 8월 25일
Copyright 2024 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.