Puntos de control
Write a query to determine available seasons and games
/ 10
Create a labeled machine learning dataset
/ 10
Create a machine learning model
/ 20
Evaluate model performance and create table
/ 10
Using skillful ML model features
/ 10
Train the new model and make evaluation
/ 10
Run a query to create a table ncaa_2018_predictions
/ 10
Run queries to create tables ncaa_2019_tournament and ncaa_2019_tournament_predictions
/ 20
Predicciones con el aprendizaje automático de Google
- GSP461
- Descripción general
- Configuración y requisitos
- Cómo abrir BigQuery Console
- March Madness de la NCAA
- Busque el conjunto de datos público de la NCAA en BigQuery
- Escriba una consulta para determinar las temporadas y los partidos disponibles
- Información sobre las etiquetas y los atributos del aprendizaje automático
- Cree un conjunto de datos de aprendizaje automático etiquetado
- Parte 1: Cree un modelo de aprendizaje automático para predecir el ganador según la clasificación y el nombre del equipo
- Cómo evaluar el rendimiento del modelo
- Cómo realizar predicciones
- ¿Cuántos aciertos tuvo nuestro modelo respecto del torneo de la NCAA de 2018?
- Los modelos solo tienen un alcance limitado
- Parte 2: Cómo usar los atributos útiles de los modelos de ML
- Obtenga una vista previa de los nuevos atributos
- Cómo interpretar las métricas seleccionadas
- Cómo entrenar el nuevo modelo
- Evalúe el rendimiento del nuevo modelo
- Cómo inspeccionar lo que aprendió el modelo
- ¡Momento de la predicción!
- Análisis de predicciones:
- ¿Dónde estaban las derrotas en marzo de 2018?
- Cómo comparar el rendimiento de los modelos
- Cómo realizar predicciones para el torneo March Madness 2019
- ¡Felicitaciones!
GSP461

Descripción general
En este lab, predecirá el ganador de un partido del torneo de básquetbol masculino de la NCAA usando BigQuery, el aprendizaje automático (ML) y un conjunto de datos.
En este lab, se usa BigQuery Machine Learning (BQML), que le permite utilizar SQL a fin de crear modelos de ML para clasificar y predecir datos.
Actividades
En este lab, aprenderá a hacer lo siguiente:
- Usar BigQuery para acceder al conjunto de datos público de la NCAA
- Explorar el conjunto de datos para familiarizarse con el esquema y el alcance de los datos disponibles
- Preparar los datos existentes y transformarlos en atributos y etiquetas
- Dividir el conjunto de datos en subconjuntos de entrenamiento y evaluación
- Usar BQML para compilar un modelo basado en el conjunto de datos de los torneos de la NCAA
- Usar el modelo creado recientemente para predecir los ganadores de los torneos de la NCAA de su ronda
Requisitos previos
Este es un lab de nivel básico. Antes de realizarlo, debe tener experiencia con SQL y con las palabras clave del lenguaje. También se recomienda tener conocimientos de BigQuery. Si necesita ponerse al día en estas áreas antes de intentar este lab, debe realizar, como mínimo, uno de los siguientes labs:
Una vez que esté preparado, desplácese hacia abajo para obtener información sobre los servicios que usará y cómo configurar correctamente el entorno de su lab.
BigQuery
BigQuery es la base de datos estadísticos de Google de bajo costo, no-ops y completamente administrada. Con BigQuery, puede consultar muchos terabytes de datos sin tener que administrar infraestructura o contar con un administrador de base de datos. BigQuery usa SQL y aprovecha el modelo prepago. Además, le permite enfocarse en el análisis de datos para buscar estadísticas significativas.
Hay un nuevo conjunto de datos disponible que contiene jugadores, equipos y partidos de básquetbol de la NCAA. Los datos de los partidos incluyen información jugada por jugada y estadísticas desde el año 2009, así como resultados finales desde 1996. En el caso de algunos equipos, los datos adicionales sobre las victorias y las derrotas se remiten a la temporada 1894-5.
Aprendizaje automático
Google Cloud ofrece una variedad de opciones de aprendizaje automático para analistas y científicos de datos. Las más populares son las siguientes:
- API de aprendizaje automático: Use API previamente entrenadas, como Cloud Vision, para tareas comunes de ML.
- AutoML: Cree modelos de ML personalizados sin codificación.
- BigQuery ML: Use su conocimiento sobre SQL para compilar rápidamente modelos de ML en el lugar donde se encuentran sus datos de BigQuery.
- AI Platform: Compile sus propios modelos de ML personalizados y póngalos en producción con la infraestructura de Google.
En este lab, usará BigQuery ML para hacer prototipos, entrenar modelos, realizar evaluaciones y predecir los "ganadores" y "perdedores" de dos equipos del torneo de básquetbol de la NCAA.
Configuración y requisitos
Configuración de Qwiklabs
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar su lab y acceder a Console
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, en el panel Detalles de conexión, se propagan las credenciales temporales que debe usar para este lab.
-
Copie el nombre de usuario y, luego, haga clic en Abrir Google Console. El lab inicia los recursos y abre otra pestaña que muestra la página Seleccione una cuenta.
Sugerencia: Abra las pestañas en ventanas separadas, una junto a la otra.
-
En la página Seleccione una cuenta, haga clic en Usar otra cuenta.
-
Se abrirá la página de acceso. Pegue el nombre de usuario que copió del panel Detalles de conexión. Luego, copie y pegue la contraseña.
Importante: Debe usar las credenciales del panel Detalles de conexión. No use sus credenciales de Qwiklabs. Si tiene una cuenta propia de GCP, no la use para este lab (evite incurrir en cargos).
-
Avance por las siguientes páginas haciendo clic en ellas:
- Acepte los Términos y Condiciones.
- No agregue opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No se registre para obtener pruebas gratuitas.


Después de un momento, se abrirá GCP Console en esta pestaña.
Cómo abrir BigQuery Console
En Google Cloud Console, abra Menú de navegación y seleccione BigQuery:
Haga clic en Listo para ir a la interfaz de usuario beta. Asegúrese de que aparezca el ID de su proyecto de GCP de Qwiklabs en el menú izquierdo de Recursos, que debería verse de la siguiente manera:
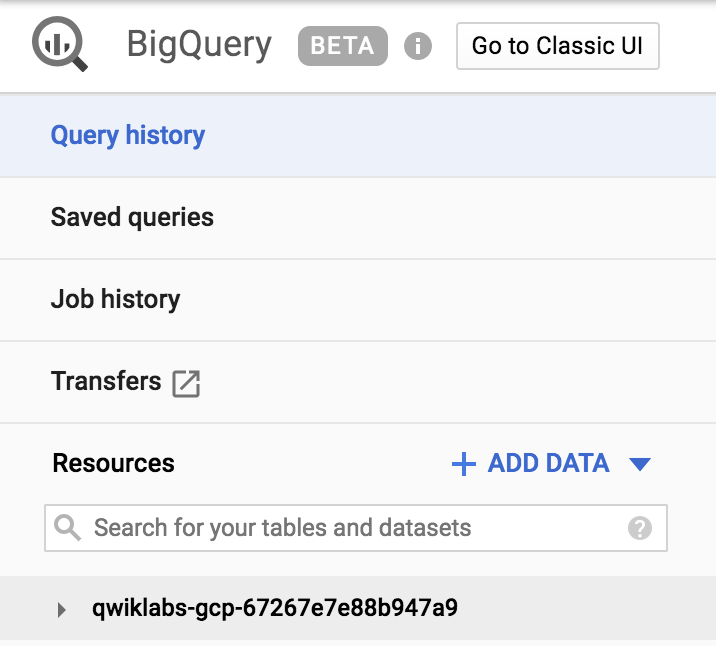
Si hace clic en la flecha desplegable junto a su proyecto, no verá ninguna base de datos ni tablas. Esto se debe a que aún no agregó ninguna a su proyecto.
Por suerte, hay muchos conjuntos de datos públicos y abiertos disponibles en BigQuery para que use. Ahora, obtendrá más información sobre el conjunto de datos de la NCAA y, luego, descubrirá cómo agregarlo a su proyecto de BigQuery.
March Madness de la NCAA
La National Collegiate Athletic Association (NCAA) organiza dos torneos importantes de básquetbol universitario todos los años en Estados Unidos para mujeres y hombres. En el torneo masculino de la NCAA que se realizó en marzo, 68 equipos participaron en partidos de eliminación directa y uno resultó ganador general del March Madness.
La NCAA ofrece un conjunto de datos público que contiene las estadísticas de los partidos de básquetbol masculinos y femeninos, y de los jugadores de la temporada y los torneos finales. Los datos de los partidos incluyen información jugada por jugada y estadísticas desde el año 2009, así como resultados finales desde 1996. En el caso de algunos equipos, los datos adicionales sobre las victorias y las derrotas se remiten a la temporada 1894-5.
Asegúrese de consultar la campaña de anuncios de marketing de Google Cloud para predecir estadísticas en vivo si desea obtener más información sobre ese conjunto de datos y lo que se hizo con él. Para estar al día con el torneo de este año, visite G.co/marchmadness.
Busque el conjunto de datos público de la NCAA en BigQuery
Asegúrese de permanecer en BigQuery Console para realizar este paso. Busque la pestaña Recursos en el menú de la izquierda y haga clic en el botón + AGREGAR DATOS. Luego, seleccione Explorar conjuntos de datos públicos.
En la barra de búsqueda, escriba "NCAA Basketball" y presione Intro. Aparecerá un resultado. Selecciónelo y, luego, haga clic en VER CONJUNTO DE DATOS:
Esto abrirá una pestaña nueva de BigQuery con el conjunto de datos cargado. Puede seguir trabajando en esa pestaña, o bien cerrarla y actualizar la instancia de BigQuery Console de la otra pestaña para ver su conjunto de datos público.
Haga clic en la flecha que aparece junto al conjunto de datos ncaa_basketball para que se muestren las tablas:
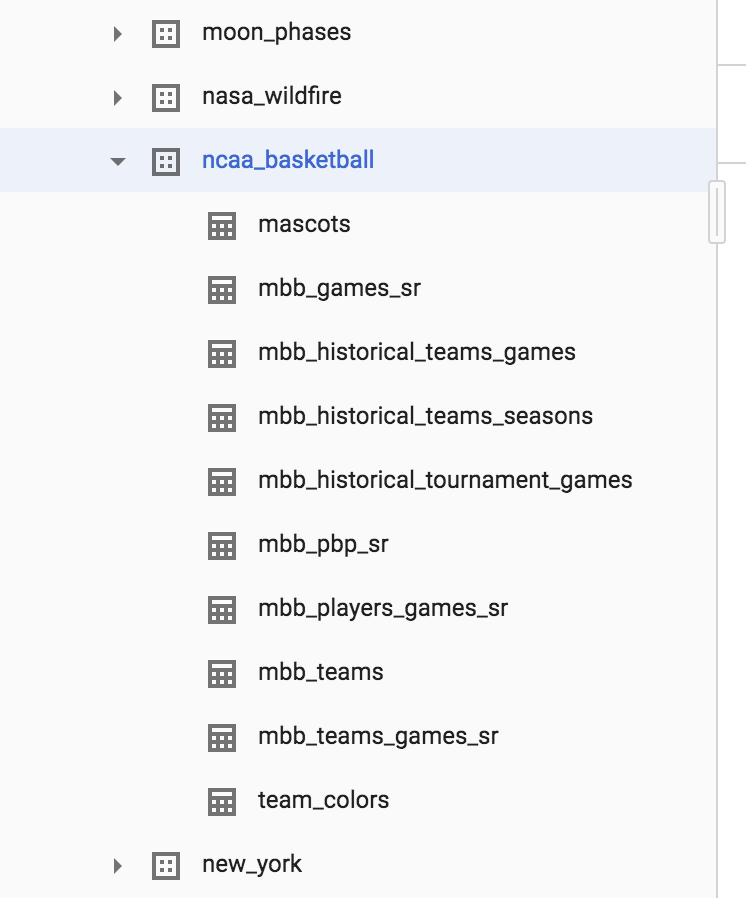
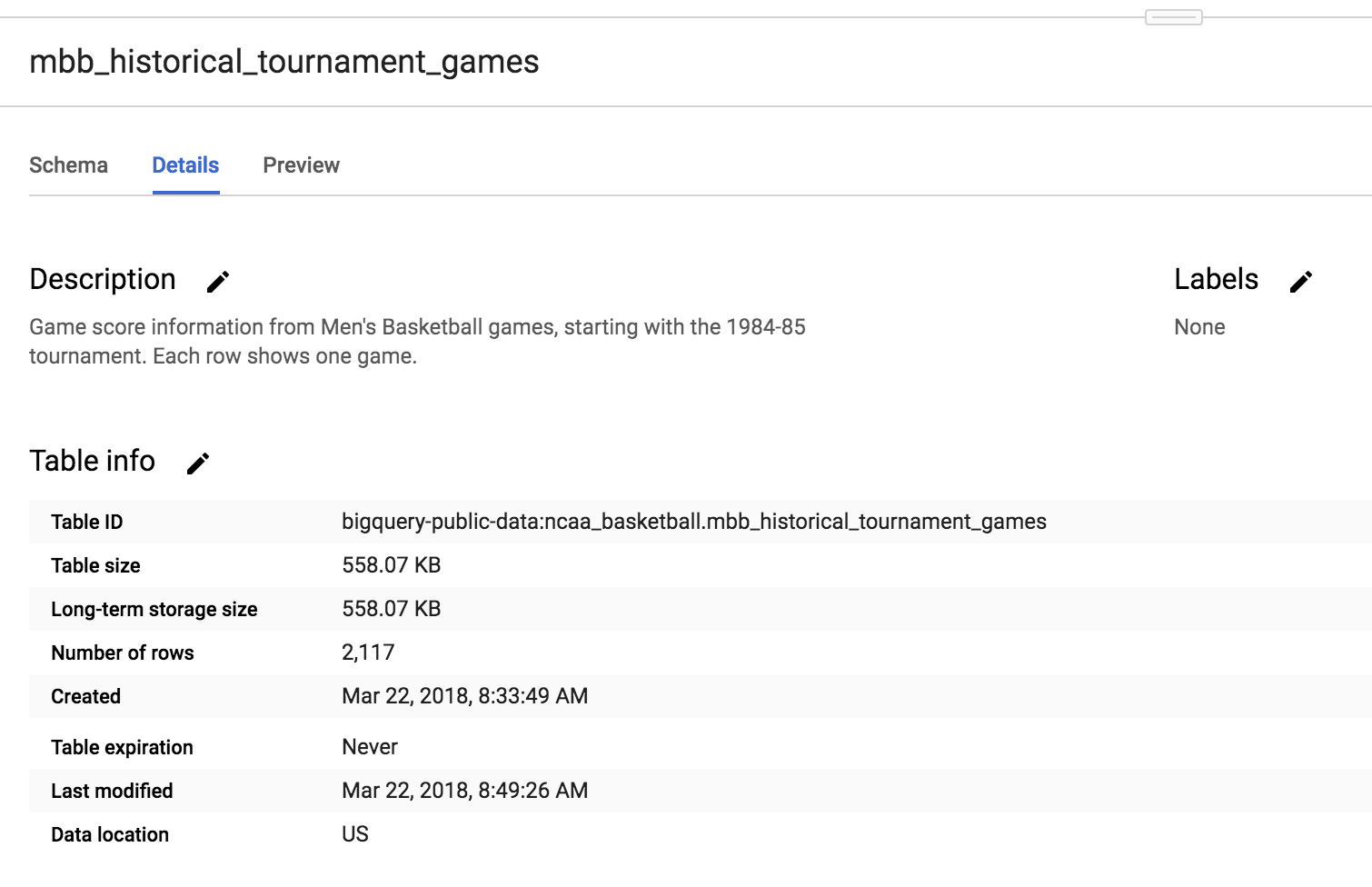
Debería ver 10 tablas en el conjunto de datos. Haga clic en mbb_historical_tournament_games y, luego, en Vista previa para ver las filas de muestra de datos. Luego, haga clic en Detalles para obtener los metadatos de la tabla. La página debería verse de esta manera:
Escriba una consulta para determinar las temporadas y los partidos disponibles
Ahora escribirá una consulta simple de SQL a fin de determinar cuántas temporadas y partidos se encuentran disponibles para explorar en nuestra tabla mbb_historical_tournament_games.
Vaya al Editor de consultas, que se encuentra arriba de la sección de detalles de la tabla. Luego, copie y pegue lo siguiente en ese campo:
SELECT
season,
COUNT(*) as games_per_tournament
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
GROUP BY season
ORDER BY season # default is Ascending (low to high)
Haga clic en Ejecutar. Algunos segundos después, debería obtener un resultado similar al siguiente:
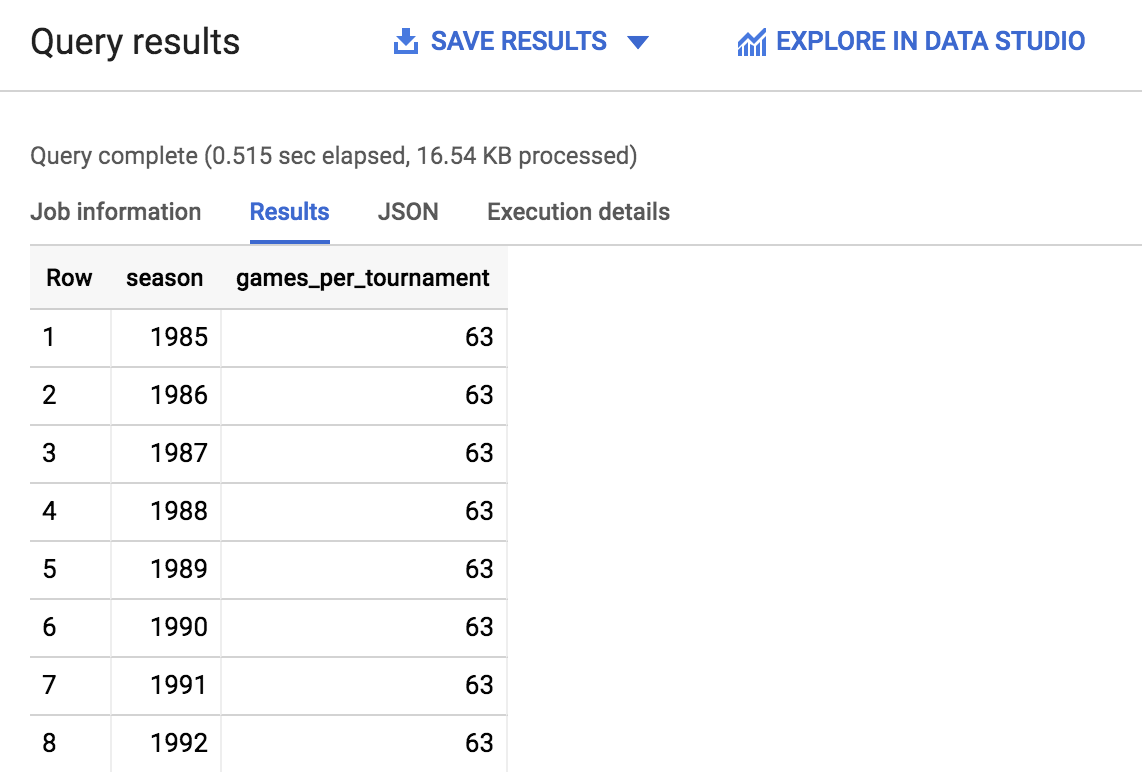
Desplácese por el resultado y tome nota de la cantidad de temporadas y de los partidos que se jugaron en cada una de ellas. Usará esa información para responder las siguientes preguntas. Además, en la parte inferior derecha, junto a las flechas de paginación, podrá ver rápidamente cuántas filas se mostraron.
Haga clic en Revisar mi progreso para verificar el objetivo.
Ponga a prueba sus conocimientos
Las siguientes preguntas de opción múltiple se usan para reforzar sus conocimientos sobre los conceptos que tratamos hasta ahora. Trate de responderlas.
Información sobre las etiquetas y los atributos del aprendizaje automático
El objetivo final de este lab es predecir el ganador de un determinado partido de básquetbol masculino de la NCAA usando datos históricos. En el aprendizaje automático, cada columna de datos que nos ayuda a determinar un resultado (en este caso, la victoria o derrota en un partido del torneo) se denomina atributo.
La columna de datos que intenta predecir se denomina etiqueta. Los modelos de aprendizaje automático "aprenden" la relación entre los atributos para predecir el resultado de una etiqueta.
A continuación, se incluyen algunos ejemplos de los atributos de su conjunto de datos histórico:
- Temporada
- Nombre del equipo
- Nombre del equipo rival
- Clasificación del equipo (ranking)
- Clasificación del equipo rival
La etiqueta que intentará predecir para los próximos partidos será game outcome, es decir, si un equipo gana o pierde.
Ponga a prueba sus conocimientos
Las siguientes preguntas de opción múltiple se usan para reforzar sus conocimientos sobre los conceptos que tratamos hasta ahora. Trate de responderlas.
Cree un conjunto de datos de aprendizaje automático etiquetado
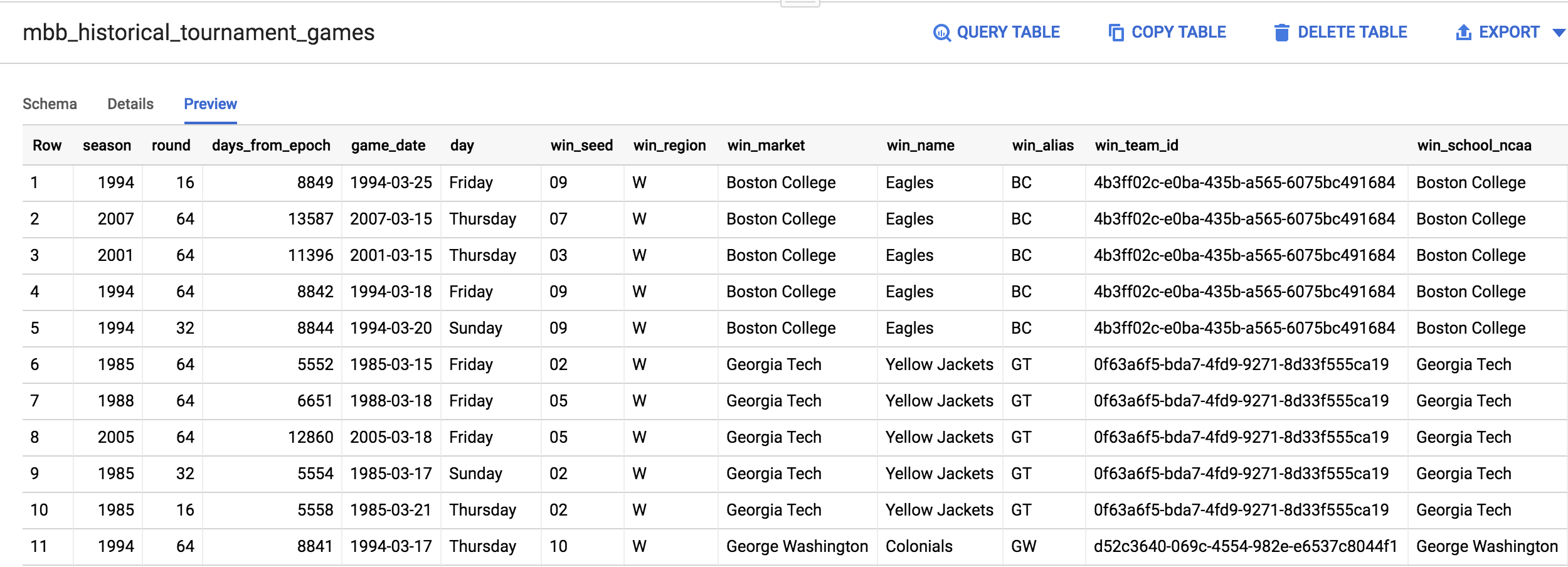
Para compilar un modelo de aprendizaje automático, se requieren muchos datos de entrenamiento de alta calidad. Por suerte, nuestro conjunto de datos de la NCAA es lo suficientemente sólido como para que podamos compilar un modelo eficaz basándonos en él. Regrese a BigQuery Console. Debería haberse detenido en el resultado de la consulta que ejecutó.
En el menú de la izquierda, abra la tabla mbb_historical_tournament_games haciendo clic en su nombre. Una vez que se cargue, haga clic en Vista previa. La página debería verse de esta manera:
Ponga a prueba sus conocimientos
Las siguientes preguntas de opción múltiple se usan para reforzar sus conocimientos sobre los conceptos que tratamos hasta ahora. Trate de responderlas.
Después de inspeccionar el conjunto de datos, observará que una fila del conjunto de datos tiene columnas para win_market y lose_market. Deberá dividir el registro de un partido en un registro para cada equipo a fin de poder etiquetar cada fila como "ganador" o "perdedor".
En el Editor de consultas, copie y pegue la siguiente consulta y haga clic en Ejecutar:
# create a row for the winning team
SELECT
# features
season, # ex: 2015 season has March 2016 tournament games
round, # sweet 16
days_from_epoch, # how old is the game
game_date,
day, # Friday
'win' AS label, # our label
win_seed AS seed, # ranking
win_market AS market,
win_name AS name,
win_alias AS alias,
win_school_ncaa AS school_ncaa,
# win_pts AS points,
lose_seed AS opponent_seed, # ranking
lose_market AS opponent_market,
lose_name AS opponent_name,
lose_alias AS opponent_alias,
lose_school_ncaa AS opponent_school_ncaa
# lose_pts AS opponent_points
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
round,
days_from_epoch,
game_date,
day,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_market AS market,
lose_name AS name,
lose_alias AS alias,
lose_school_ncaa AS school_ncaa,
# lose_pts AS points,
win_seed AS opponent_seed, # ranking
win_market AS opponent_market,
win_name AS opponent_name,
win_alias AS opponent_alias,
win_school_ncaa AS opponent_school_ncaa
# win_pts AS opponent_points
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
Debería obtener el siguiente resultado:
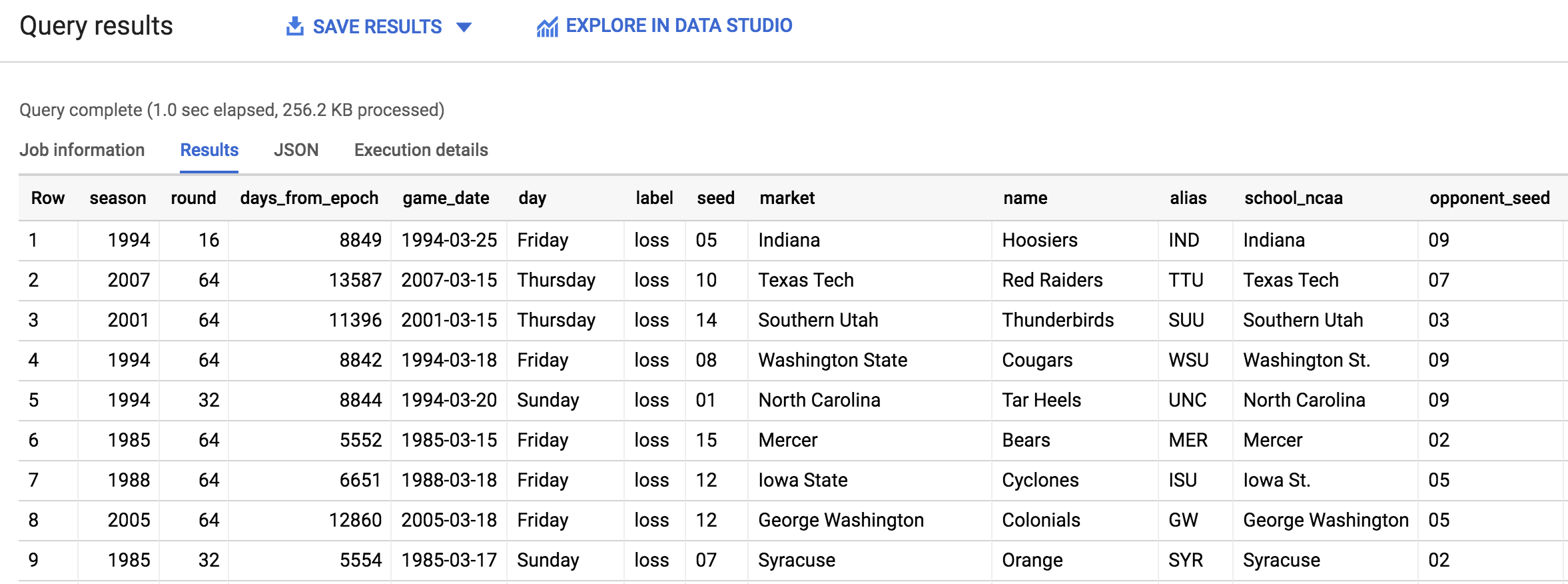
Haga clic en Revisar mi progreso para verificar el objetivo.
Ahora que conoce qué atributos se encuentran disponibles a partir del resultado, responda la siguiente pregunta para reforzar sus conocimientos del conjunto de datos.
Parte 1: Cree un modelo de aprendizaje automático para predecir el ganador según la clasificación y el nombre del equipo
Ahora que ya exploramos nuestros datos, es momento de entrenar un modelo de aprendizaje automático. Utilizando su mejor juicio, responda la pregunta que aparece a continuación para orientarse en esta sección.
Cómo elegir un tipo de modelo
Para este problema en particular, compilará un modelo de clasificación. Como tiene dos clases, victoria o derrota, también se denomina modelo de clasificación binaria. Un equipo puede ganar o perder un partido.
Si lo desea, después del lab, puede predecir la cantidad total de puntos que anotará un equipo con un modelo de predicción, pero ese no es nuestro enfoque aquí.
Una manera simple de saber si está prediciendo o clasificando es mirar el tipo de etiqueta (columna) de los datos que está intentando predecir:
- Si se trata de una columna numérica (como unidades vendidas o puntos en un partido), significa que está prediciendo.
- Si se trata del valor de una string, entonces está clasificando (esa fila es de esta clase o de esta otra).
- Si tiene más de dos clases (como victoria, derrota o empate), está haciendo una clasificación de clases múltiples.
Nuestro modelo de clasificación llevará a cabo el aprendizaje automático con un modelo estadístico muy popular llamado Regresión logística. Necesitamos un modelo que genere una probabilidad para cada valor posible de etiqueta discreta, el que en nuestro caso es una "victoria" o una "derrota". La regresión logística es un buen tipo de modelo para comenzar con este objetivo. Lo positivo es que el modelo de ML hará todos los cálculos y la optimización durante el entrenamiento de modelos, una actividad en la que las computadoras llegan a ser infalibles.
Cómo crear un modelo de aprendizaje automático con BigQuery ML
A fin de crear nuestro modelo de clasificación en BigQuery, solo necesitamos escribir la instrucción de SQL CREATE MODEL y proporcionar algunas opciones.
Sin embargo, antes de poder crear el modelo, necesitamos un lugar para almacenarlo en nuestro proyecto.
En el menú de la izquierda, seleccione su proyecto de Qwiklabs de la lista de Recursos:
Luego, en el extremo derecho, haga clic en CREAR CONJUNTO DE DATOS. Se abrirá un menú. Configure el ID de su conjunto de datos como bracketology y haga clic en Crear conjunto de datos:
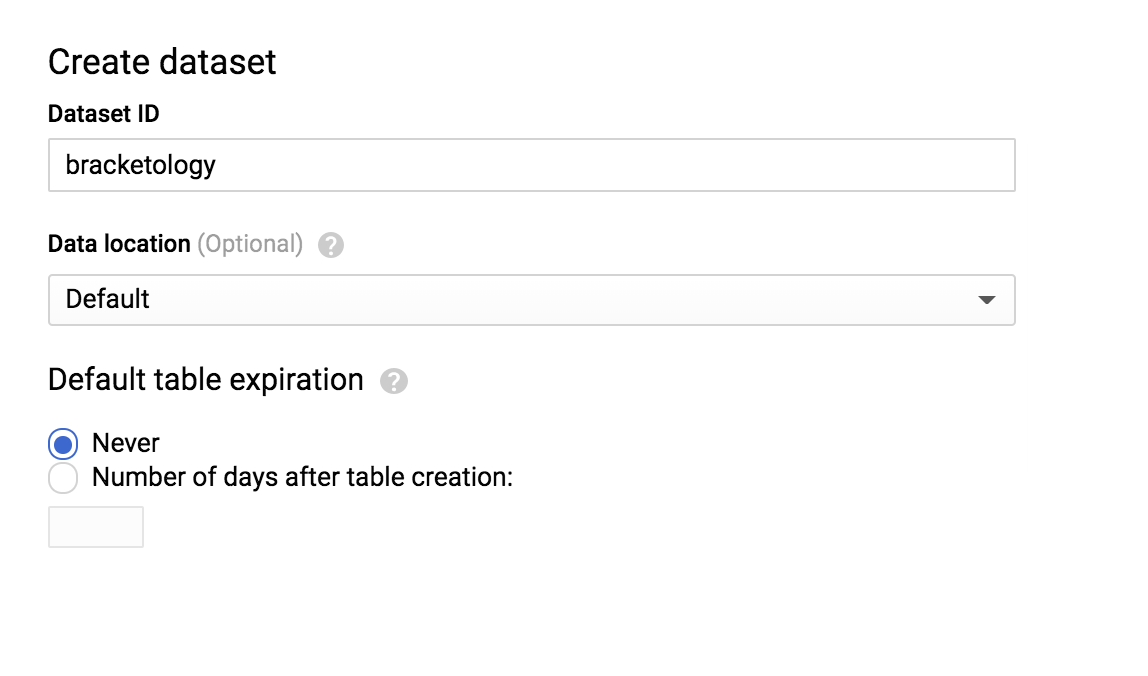
Ahora ejecute el siguiente comando en el Editor de consultas:
CREATE OR REPLACE MODEL
`bracketology.ncaa_model`
OPTIONS
( model_type='logistic_reg') AS
# create a row for the winning team
SELECT
# features
season,
'win' AS label, # our label
win_seed AS seed, # ranking
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
WHERE season <= 2017
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
# now we split our dataset with a WHERE clause so we can train on a subset of data and then evaluate and test the model's performance against a reserved subset so the model doesn't memorize or overfit to the training data.
# tournament season information from 1985 - 2017
# here we'll train on 1985 - 2017 and predict for 2018
WHERE season <= 2017
En nuestro código, observará que solo se requieren unas pocas líneas de SQL para crear el modelo. Una de las opciones más importantes es elegir el tipo de modelo logistic_reg para nuestra tarea de clasificación.
Entrenar el modelo tardará entre 3 y 5 minutos. Debería obtener el siguiente resultado cuando finalice el trabajo:

A la derecha de Console, haga clic en el botón Ir al modelo.
Haga clic en Revisar mi progreso para verificar el objetivo.
Vea los detalles de entrenamiento de modelos
Ahora que se encuentra en los detalles del modelo, desplácese hasta la sección Opciones de entrenamiento y vea las iteraciones reales que realizó el modelo para el entrenamiento. Si tiene experiencia con el aprendizaje automático, observe que puede personalizar todos esos hiperparámetros (opciones configuradas antes de ejecutar el modelo) definiendo su valor en la declaración OPTIONS. Si no tiene experiencia, BigQuery ML configurará valores inteligentes predeterminados para cualquier opción que no esté configurada.
Si desea obtener más información, consulte la lista de opciones de modelos de BigQuery ML.
Vea las estadísticas del entrenamiento de modelos
Los modelos de aprendizaje automático "aprenden" la asociación entre los atributos conocidos y las etiquetas desconocidas. Como puede suponer, algunos atributos, como la "clasificación" o el "nombre de la escuela", pueden ser de mayor ayuda para determinar una victoria o una derrota que otras columnas de datos (atributos), como el día de la semana en el que se juega el partido. Los modelos de aprendizaje automático inician el proceso de entrenamiento sin esa intuición y, por lo general, aleatorizarán la ponderación de cada atributo.
Durante el proceso de entrenamiento, el modelo optimizará una ruta para ponderar cada atributo de la mejor manera posible. Con cada ejecución, se intenta minimizar la Pérdida de datos de entrenamiento y la Pérdida de datos de evaluación. Si alguna vez descubre que la pérdida final de la evaluación es mucho mayor que la de entrenamiento, significa que su modelo sobreajusta o memoriza sus datos de entrenamiento en lugar de aprender relaciones generalizables.
Puede ver cuántas ejecuciones de entrenamiento realiza el modelo haciendo clic en la pestaña Estadísticas del modelo o Entrenamiento. Durante nuestra ejecución en particular, el modelo completó 3 iteraciones de entrenamiento en aproximadamente 20 segundos. Es posible que el suyo varíe.
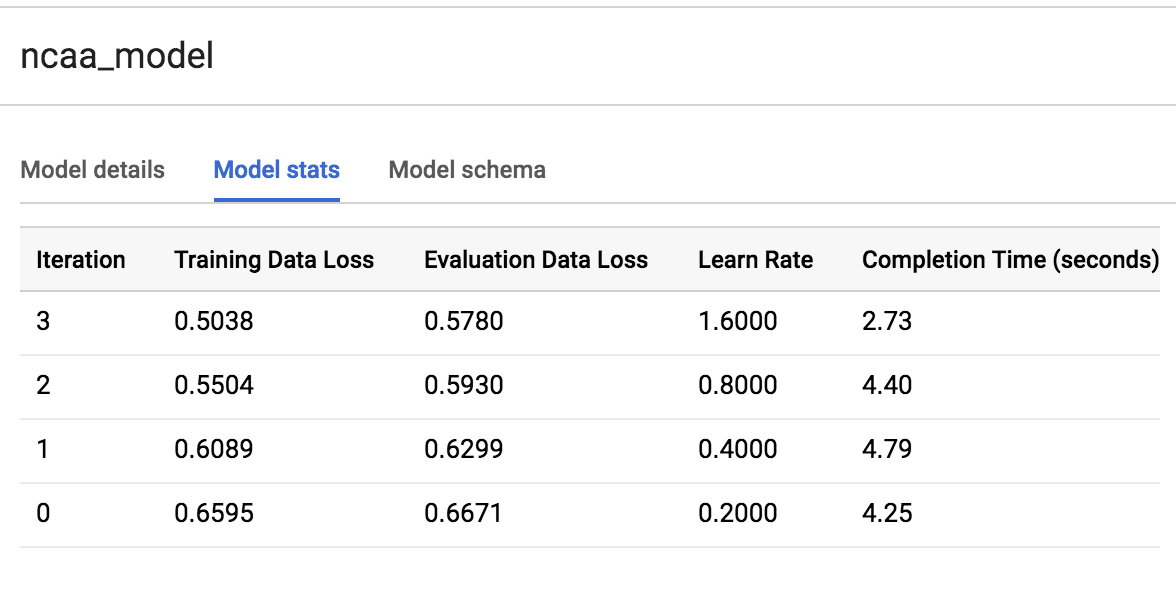
Vea lo que aprendió el modelo sobre nuestros atributos
Después del entrenamiento, podrá ver qué atributos proporcionaron un mayor valor al modelo mediante la inspección de las ponderaciones. Ejecute el siguiente comando en el Editor de consultas:
SELECT
category,
weight
FROM
UNNEST((
SELECT
category_weights
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model`)
WHERE
processed_input = 'seed')) # try other features like 'school_ncaa'
ORDER BY weight DESC
El resultado debería ser similar al siguiente:
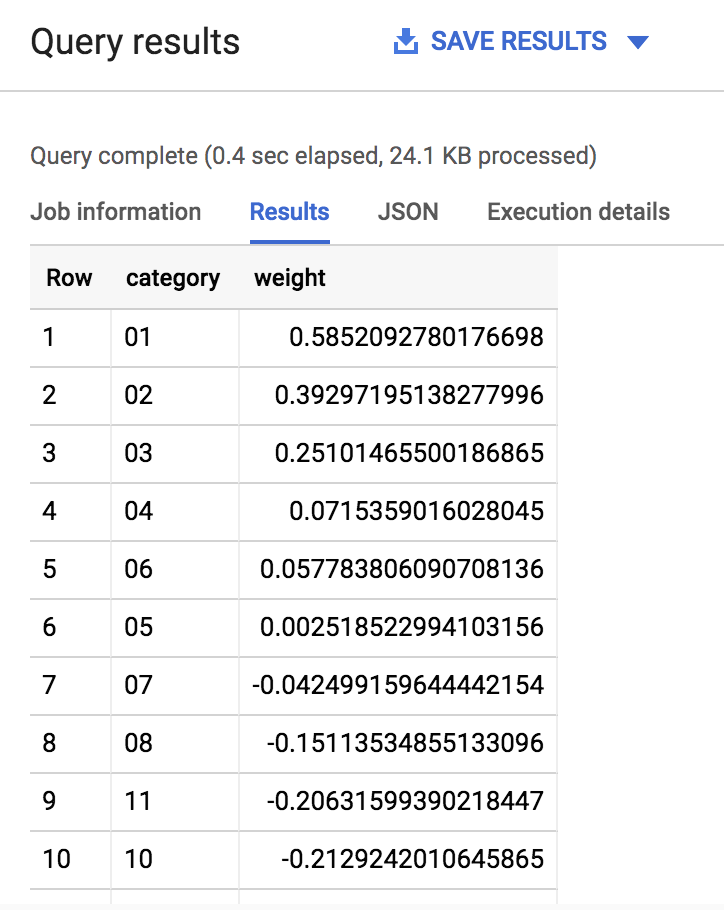
Como puede ver, si la clasificación de un equipo es muy baja (1, 2 o 3) o muy alta (14, 15 o 16), el modelo le proporciona una ponderación significativa (lo máximo es 1.0) para determinar el resultado de victorias y derrotas. De forma intuitiva, esto tiene sentido porque esperamos que los equipos con una clasificación muy baja tengan un buen rendimiento en el torneo.
La verdadera magia del aprendizaje automático es que no creamos un montón de enunciados IF THEN codificados en SQL que le indican al modelo que si la condición IF THEN en la clasificación es 1, el equipo tiene un 80% más de probabilidades de ganar. El aprendizaje automático elimina las reglas codificadas y la lógica, y aprende esas relaciones por sí mismo. Para obtener más información, consulte la documentación de ponderaciones sintácticas de BQML.
Cómo evaluar el rendimiento del modelo
A fin de evaluar el rendimiento del modelo, puede ejecutar el fragmento de código ML.EVALUATE en un modelo entrenado. Ejecute el siguiente comando en el Editor de consultas:
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model`)
Debería obtener un resultado similar al siguiente:

El valor tendrá una exactitud de alrededor del 69%. Aunque es mejor que lanzar una moneda a la suerte, quedan aspectos por mejorar.
Cómo realizar predicciones
Ahora que entrenó un modelo con datos históricos hasta la temporada 2017 inclusive (todos los datos que tenía), es hora de realizar las predicciones para la temporada 2018. Su equipo de científicos de datos le proporcionó los resultados del torneo 2018 en una tabla aparte que no tiene en su conjunto de datos original.
Hacer predicciones es tan simple como llamar a ML.PREDICT en un modelo entrenado y pasar el conjunto de datos sobre el que desea realizar la predicción.
Ejecute el siguiente comando en el Editor de consultas:
CREATE OR REPLACE TABLE `bracketology.predictions` AS (
SELECT * FROM ML.PREDICT(MODEL `bracketology.ncaa_model`,
# predicting for 2018 tournament games (2017 season)
(SELECT * FROM `data-to-insights.ncaa.2018_tournament_results`)
)
)
Algunos segundos después, debería obtener el siguiente resultado:

Haga clic en Revisar mi progreso para verificar el objetivo.
Ahora verá su conjunto de datos original, además de tres columnas nuevas:
- Etiqueta de predicción
- Opciones de etiqueta de predicción
- Probabilidad de etiqueta de predicción
Como usted ya conoce los resultados del torneo March Madness 2018, veamos cómo le fue al modelo con las predicciones. Sugerencia: Si quiere predecir el torneo March Madness de este año, simplemente pase un conjunto de datos con las clasificaciones y los nombres de los equipos de 2019. Desde luego, la columna de etiquetas estará vacía, ya que esos partidos aún no se jugaron (eso es lo que va a predecir).
¿Cuántos aciertos tuvo nuestro modelo respecto del torneo de la NCAA de 2018?
Ejecute el siguiente comando en el Editor de consultas:
SELECT * FROM `bracketology.predictions`
WHERE predicted_label <> label
Debería obtener un resultado similar al siguiente:
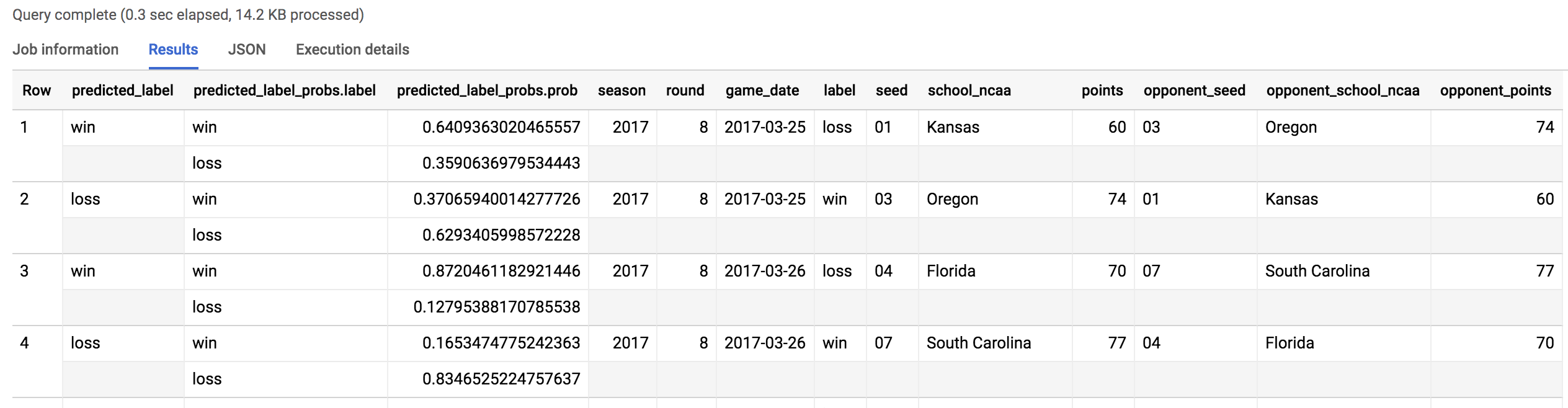
De un total de 134 predicciones (67 partidos del torneo), nuestro modelo se equivocó 38 veces. Obtuvo un 70% total de aciertos en los partidos del torneo 2018.
Los modelos solo tienen un alcance limitado
Hay muchos otros factores y atributos que influyen en las victorias estrechas y las derrotas increíbles de cualquier torneo March Madness que a un modelo le costaría mucho predecir.
Busquemos la mayor derrota del torneo 2017 según el modelo. Veremos dónde el modelo predice con una certeza de más del 80% y se equivoca.
Ejecute el siguiente comando en el Editor de consultas:
SELECT
model.label AS predicted_label,
model.prob AS confidence,
predictions.label AS correct_label,
game_date,
round,
seed,
school_ncaa,
points,
opponent_seed,
opponent_school_ncaa,
opponent_points
FROM `bracketology.predictions` AS predictions,
UNNEST(predicted_label_probs) AS model
WHERE model.prob > .8 AND predicted_label <> predictions.label
El resultado debería ser similar al siguiente:
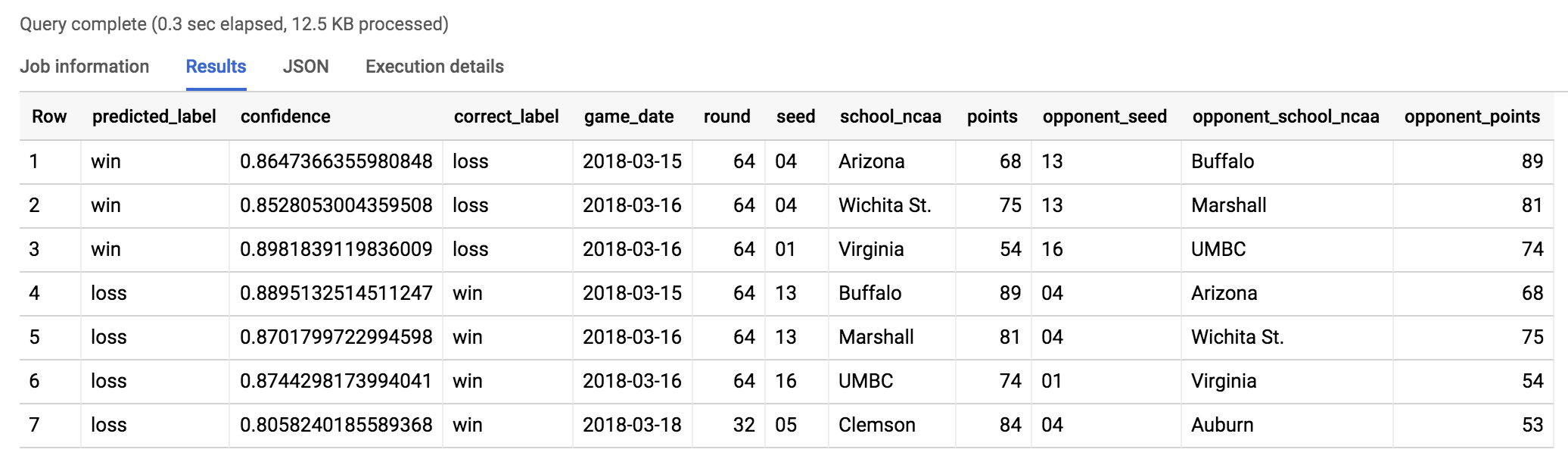
Mire este video para ver lo que sucedió realmente.
Después del partido, el entrenador Odom (UMBC) declaró: "Es increíble. Es todo lo que se puede decir".
Resumen
- Creó un modelo de aprendizaje automático para predecir el resultado de los partidos.
- Evaluó el rendimiento y logró una exactitud del 69% con la clasificación y el nombre del equipo como atributos principales.
- Predijo los resultados del torneo 2018.
- Analizó los resultados para obtener estadísticas.
Nuestro próximo desafío será compilar un modelo más efectivo SIN usar la clasificación y el nombre del equipo como atributos.
Parte 2: Cómo usar los atributos útiles de los modelos de ML
En la segunda parte de este lab, compilará un segundo modelo de ML con atributos detallados que se proporcionaron recientemente.
Ahora que ya está familiarizado con la compilación de modelos de ML mediante el uso BigQuery ML, su equipo de científicos de datos le proporcionó un nuevo conjunto de datos jugada por jugada en el que crearon métricas nuevas de equipos para que aprenda su modelo. Estos incluyen:
- Eficiencia en el tiempo para anotar según el análisis histórico jugada por jugada
- Posesión del balón en el transcurso del tiempo
Cree un conjunto de datos de ML nuevo con estos atributos útiles
Ejecute el siguiente comando en el Editor de consultas:
# create training dataset:
# create a row for the winning team
CREATE OR REPLACE TABLE `bracketology.training_new_features` AS
WITH outcomes AS (
SELECT
# features
season, # 1994
'win' AS label, # our label
win_seed AS seed, # ranking # this time without seed even
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# create a separate row for the losing team
SELECT
# features
season, # 1994
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# add in 2018 tournament game results not part of the public dataset:
SELECT
season,
label,
seed,
school_ncaa,
opponent_seed,
opponent_school_ncaa
FROM
`data-to-insights.ncaa.2018_tournament_results`
)
SELECT
o.season,
label,
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM outcomes AS o
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS team
ON o.school_ncaa = team.team AND o.season = team.season
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS opp
ON o.opponent_school_ncaa = opp.team AND o.season = opp.season
Algunos segundos después, debería obtener el siguiente resultado:

Haga clic en Revisar mi progreso para verificar el objetivo.
Obtenga una vista previa de los nuevos atributos
Haga clic en el botón Ir a la tabla que se encuentra a la derecha de Console. Luego, haga clic en la pestaña Vista previa.
Su tabla debería ser similar a la siguiente:
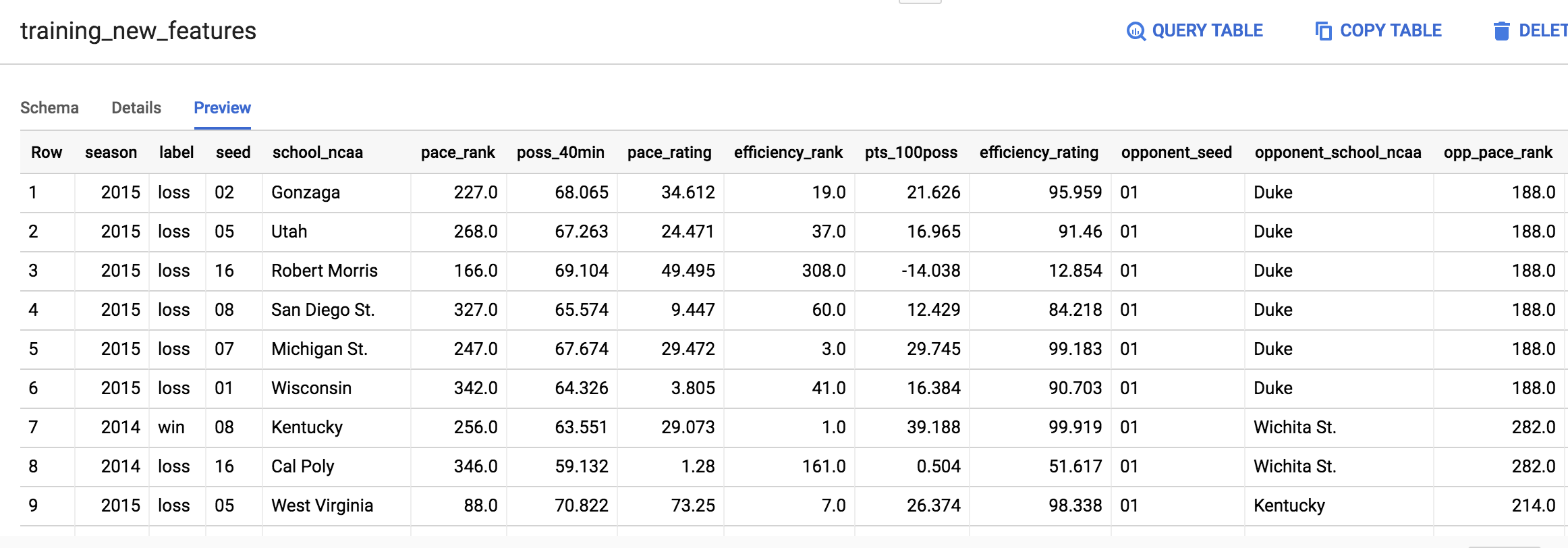
No se preocupe si su resultado no es igual a la captura de pantalla anterior.
Cómo interpretar las métricas seleccionadas
Ahora conocerá algunas etiquetas importantes que nos ayudan a hacer predicciones.
opp_efficiency_rank
Clasificación de la eficiencia del rival: De todos los equipos, indica la clasificación que tiene nuestro rival para anotar de manera eficiente en el transcurso del tiempo (puntos por cada 100 posesiones del balón). Cuanto más baja, mejor.
opp_pace_rank
Clasificación de la velocidad del rival: De todos los equipos, indica la clasificación que tiene nuestro rival en cuanto a la posesión del balón (cantidad de posesiones en 40 minutos). Cuanto más baja, mejor.
Ahora que tiene atributos esclarecedores sobre lo bien que puede anotar y manejar el balón un equipo, entrenemos nuestro segundo modelo.
Como medida adicional para evitar que su modelo "memorice los equipos buenos del pasado", excluya el nombre del equipo y la clasificación de este próximo modelo y enfóquese solo en las métricas.
Cómo entrenar el nuevo modelo
Ejecute el siguiente comando en el Editor de consultas:
CREATE OR REPLACE MODEL
`bracketology.ncaa_model_updated`
OPTIONS
( model_type='logistic_reg') AS
SELECT
# this time, dont train the model on school name or seed
season,
label,
# our pace
poss_40min,
pace_rank,
pace_rating,
# opponent pace
opp_poss_40min,
opp_pace_rank,
opp_pace_rating,
# difference in pace
pace_rank_diff,
pace_stat_diff,
pace_rating_diff,
# our efficiency
pts_100poss,
efficiency_rank,
efficiency_rating,
# opponent efficiency
opp_pts_100poss,
opp_efficiency_rank,
opp_efficiency_rating,
# difference in efficiency
eff_rank_diff,
eff_stat_diff,
eff_rating_diff
FROM `bracketology.training_new_features`
# here we'll train on 2014 - 2017 and predict on 2018
WHERE season BETWEEN 2014 AND 2017 # between in SQL is inclusive of end points
Algunos segundos después, debería obtener un resultado similar al siguiente:
Evalúe el rendimiento del nuevo modelo
Para evaluar el rendimiento de su modelo, ejecute el siguiente comando en el Editor de consultas:
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model_updated`)
Debería obtener un resultado similar al siguiente:

¡Vaya! Acaba de entrenar un modelo nuevo con atributos diferentes y de aumentar su exactitud a aproximadamente un 75%, o un aumento del 5% en comparación con el modelo original.
Una de las lecciones más importantes del aprendizaje automático es que su conjunto de datos de atributos de alta calidad puede marcar una gran diferencia en la exactitud de su modelo.
Haga clic en Revisar mi progreso para verificar el objetivo.
Cómo inspeccionar lo que aprendió el modelo
¿Qué atributos pondera más el modelo en el resultado de una victoria o derrota? Descúbralo ejecutando el siguiente comando en el Editor de consultas:
SELECT
*
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model_updated`)
ORDER BY ABS(weight) DESC
Debería obtener un resultado similar al siguiente:
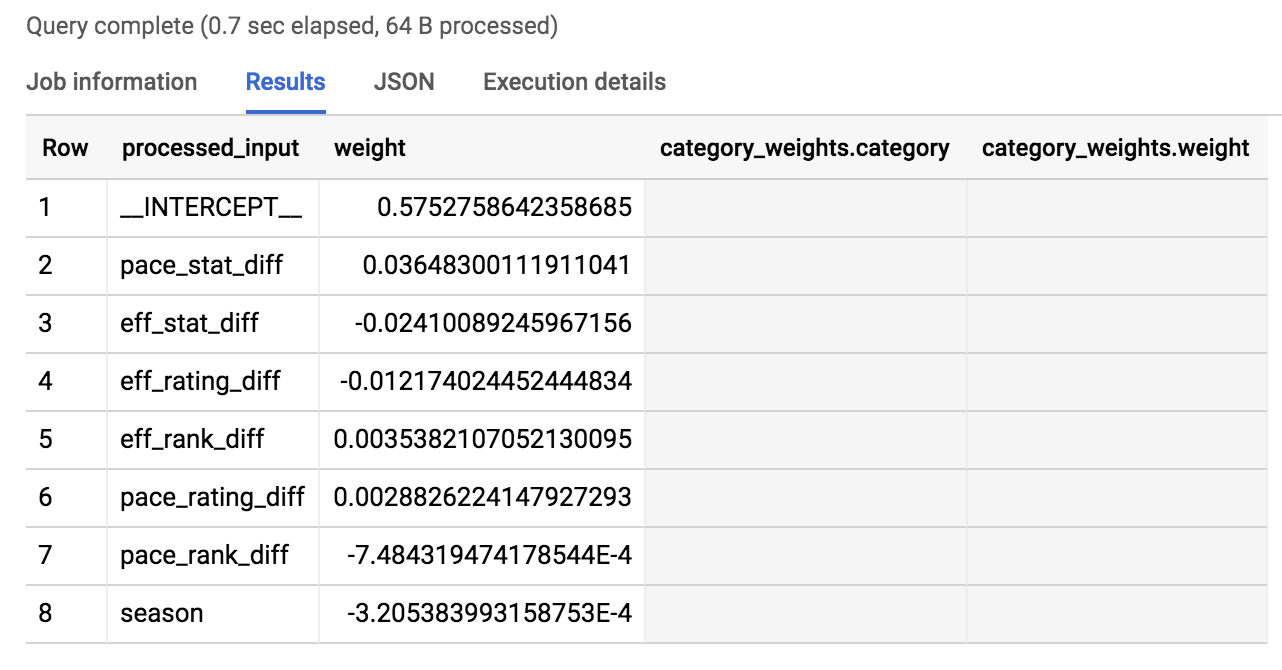
Tomamos el valor absoluto de los pesos en nuestro pedido para que aparezca en primer lugar lo más determinante (para una victoria o una derrota).
Como puede ver en los resultados, los 3 principales son pace_stat_diff, eff_stat_diff y eff_rating_diff. Pasemos a explorarlos un poco más.
pace_stat_diff
Indica qué tan diferente fue, entre los equipos, la estadística real de posesiones en 40 minutos. Según el modelo, es el controlador principal en la selección del resultado del partido.
eff_stat_diff
Indica qué tan diferente fue, entre los equipos, la estadística real de puntos netos por cada 100 posesiones.
eff_rating_diff
Indica qué tan diferente fue, entre los equipos, la calificación normalizada de eficiencia para anotar.
¿Qué fue lo que el modelo no tuvo demasiado en cuenta en sus predicciones? La temporada. Era lo último en el resultado de las ponderaciones pedidas que se mencionaron anteriormente. Lo que indica el modelo es que la temporada (2013, 2014 y 2015) no es tan útil para predecir el resultado de los partidos. No hubo nada mágico en el año "2014" para ningún equipo.
Una estadística interesante es que el modelo valoró la velocidad de un equipo (qué tan bien pudieron controlar el balón) por sobre la eficiencia con la que un equipo puede anotar.
¡Momento de la predicción!
Ejecute el siguiente comando en el Editor de consultas:
CREATE OR REPLACE TABLE `bracketology.ncaa_2018_predictions` AS
# let's add back our other data columns for context
SELECT
*
FROM
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
SELECT
* # include all columns now (the model has already been trained)
FROM `bracketology.training_new_features`
WHERE season = 2018
))
Debería obtener un resultado similar al siguiente:

Haga clic en Revisar mi progreso para verificar el objetivo.
Análisis de predicciones:
Dado que conoce el resultado correcto del partido, puede ver en qué parte el modelo hizo una predicción errónea con el nuevo conjunto de datos de prueba. Ejecute el siguiente comando en el Editor de consultas:
SELECT * FROM `bracketology.ncaa_2018_predictions`
WHERE predicted_label <> label
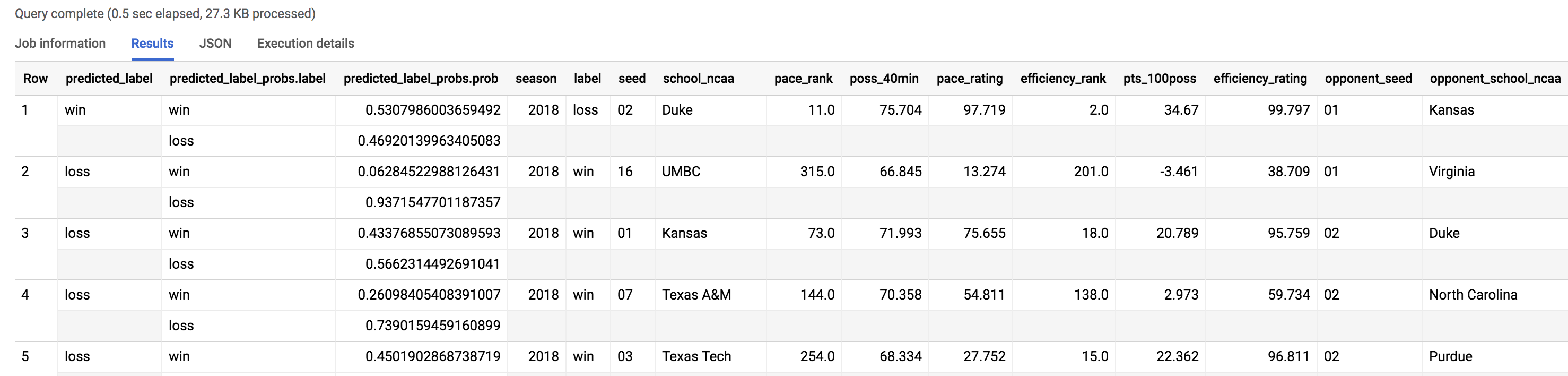
Como puede ver en la cantidad de registros que muestra la consulta, el modelo erró en 48 enfrentamientos (24 partidos) de la cantidad total del torneo con una exactitud del 64% para el año 2018. Ese año debe haber sido un año agitado. Veamos las derrotas.
¿Dónde estaban las derrotas en marzo de 2018?
Ejecute el siguiente comando en el Editor de consultas:
SELECT
CONCAT(school_ncaa, " was predicted to ",IF(predicted_label="loss","lose","win")," ",CAST(ROUND(p.prob,2)*100 AS STRING), "% but ", IF(n.label="loss","lost","won")) AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label <> n.label # model got it wrong
AND p.prob > .75 # by more than 75% confidence
ORDER BY prob DESC
Debería obtener un resultado similar al siguiente:
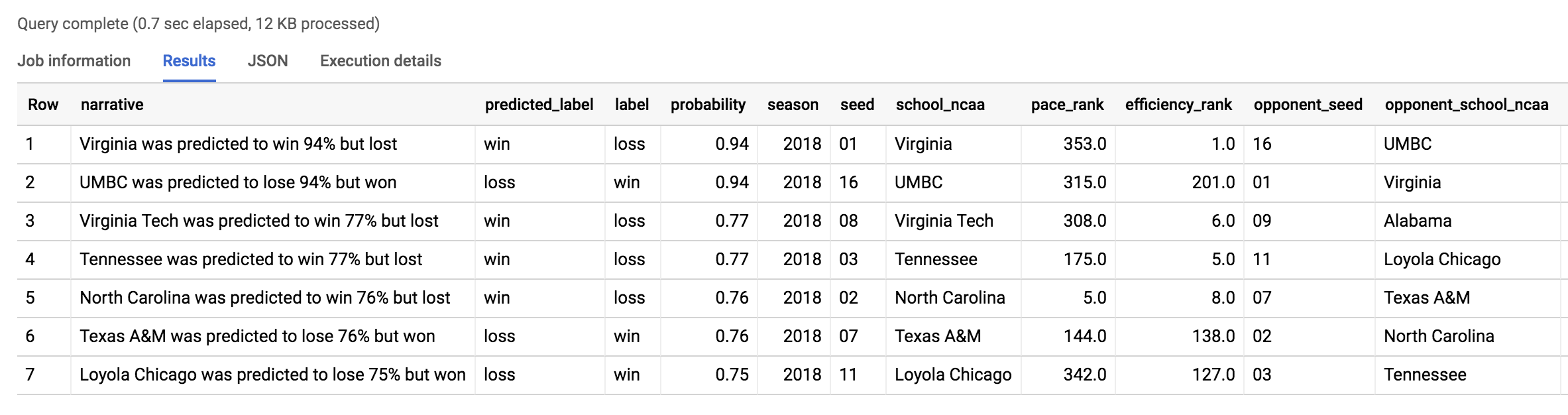
La derrota más importante fue la misma que descubrió nuestro modelo anterior: UMBC contra Virginia. En general, 2018 fue un año de grandes derrotas. ¿2019 será igual de agitado?
Cómo comparar el rendimiento de los modelos
¿Qué ocurre con los casos en los que el modelo básico (que compara clasificaciones) erró, pero el modelo avanzado acertó? Ejecute el siguiente comando en el Editor de consultas:
SELECT
CONCAT(opponent_school_ncaa, " (", opponent_seed, ") was ",CAST(ROUND(ROUND(p.prob,2)*100,2) AS STRING),"% predicted to upset ", school_ncaa, " (", seed, ") and did!") AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank,
(CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) AS seed_diff
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label = 'loss'
AND predicted_label = n.label # model got it right
AND p.prob >= .55 # by 55%+ confidence
AND (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) > 2 # seed difference magnitude
ORDER BY (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) DESC
Debería obtener un resultado similar al siguiente:

El modelo predijo que Florida St. (09) derrotaría a Xavier (01), y así fue.
El nuevo modelo predijo la derrota de manera correcta (incluso cuando la clasificación indicaba lo contrario) basándose en los nuevos atributos útiles, como la velocidad y la eficiencia para anotar. Mire los momentos destacados del partido en YouTube.
Cómo realizar predicciones para el torneo March Madness 2019
Ahora que conocemos los equipos y las clasificaciones de marzo 2019, hagamos predicciones del resultado de los próximos partidos.
Explore los datos del año 2019
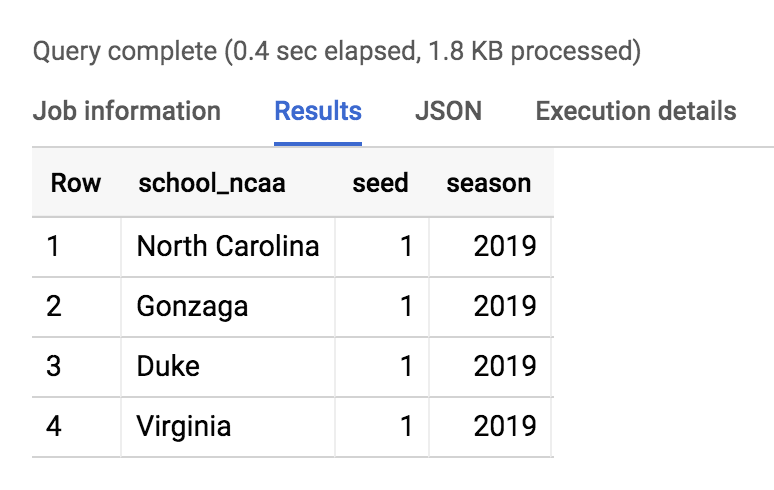
Ejecute la siguiente consulta para ver las clasificaciones principales:
SELECT * FROM `data-to-insights.ncaa.2019_tournament_seeds` WHERE seed = 1
Debería obtener un resultado similar al siguiente:
Cree una matriz de todos los partidos posibles
Dado que no sabemos qué equipos se enfrentarán a medida que avance el torneo, simplemente haremos que todos compitan entre sí.
En SQL, una manera simple de hacer que un solo equipo se enfrente a todos los de la tabla es usar el fragmento CROSS JOIN.
Ejecute la siguiente consulta para obtener todos los partidos posibles del torneo:
SELECT
NULL AS label,
team.school_ncaa AS team_school_ncaa,
team.seed AS team_seed,
opp.school_ncaa AS opp_school_ncaa,
opp.seed AS opp_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
Agregue las estadísticas de los equipos de 2018 (velocidad y eficiencia)
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament` AS
WITH team_seeds_all_possible_games AS (
SELECT
NULL AS label,
team.school_ncaa AS school_ncaa,
team.seed AS seed,
opp.school_ncaa AS opponent_school_ncaa,
opp.seed AS opponent_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
)
, add_in_2018_season_stats AS (
SELECT
team_seeds_all_possible_games.*,
# bring in features from the 2018 regular season for each team
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE school_ncaa = team AND season = 2018) AS team,
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE opponent_school_ncaa = team AND season = 2018) AS opp
FROM team_seeds_all_possible_games
)
# Preparing 2019 data for prediction
SELECT
label,
2019 AS season, # 2018-2019 tournament season
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM add_in_2018_season_stats
Realice las predicciones
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament_predictions` AS
SELECT
*
FROM
# let's predicted using the newer model
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
# let's predict on March 2019 tournament games:
SELECT * FROM `bracketology.ncaa_2019_tournament`
))
Haga clic en Revisar mi progreso para verificar el objetivo.
Obtenga las predicciones
SELECT
p.label AS prediction,
ROUND(p.prob,3) AS confidence,
school_ncaa,
seed,
opponent_school_ncaa,
opponent_seed
FROM `bracketology.ncaa_2019_tournament_predictions`,
UNNEST(predicted_label_probs) AS p
WHERE p.prob >= .5
AND school_ncaa = 'Duke'
ORDER BY seed, opponent_seed
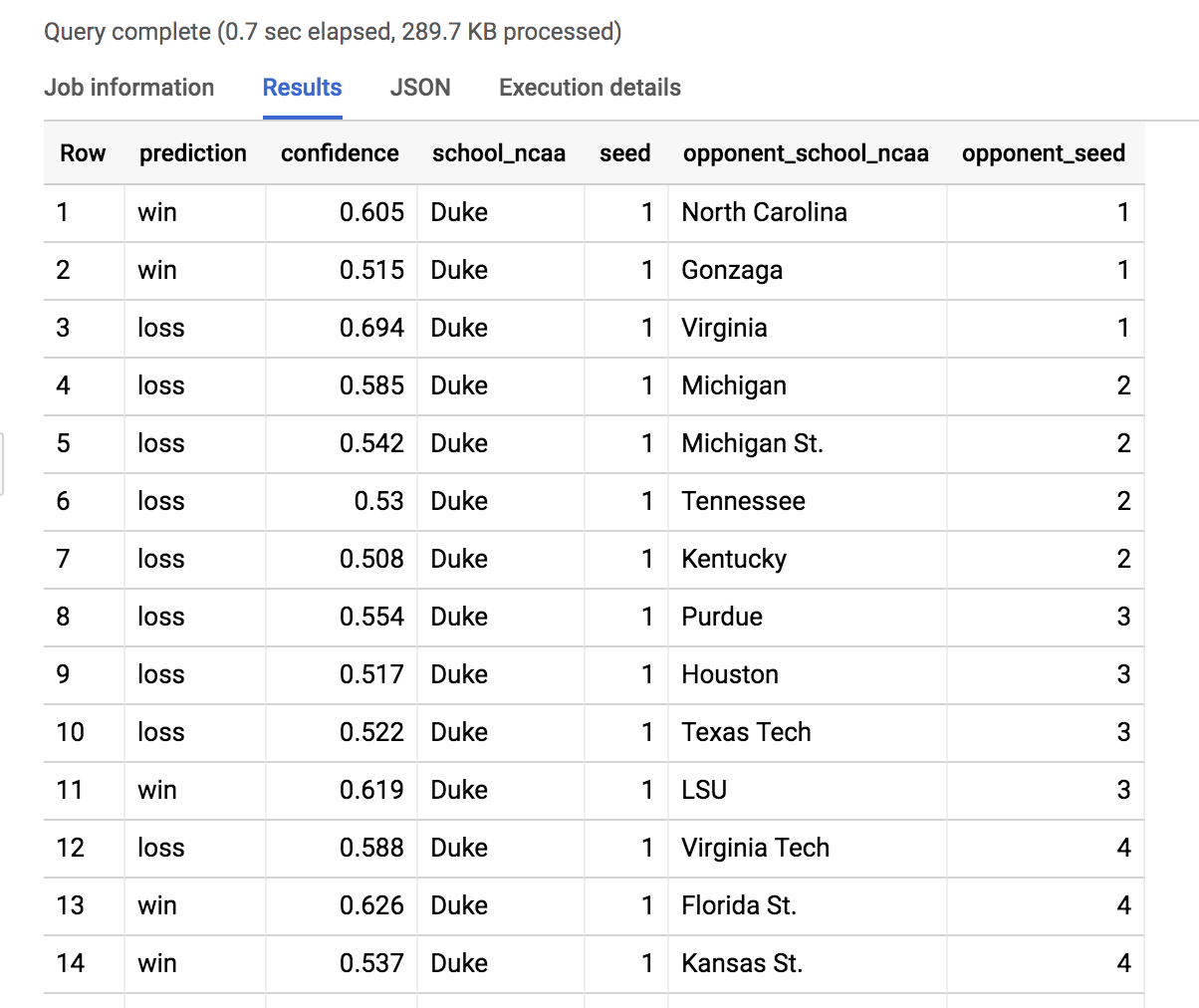
Aquí filtramos los resultados del modelo para ver todos los partidos posibles de Duke. Desplácese para ver el partido de Duke contra North Dakota St.
Estadística: Duke (1) tiene un 88.5% de probabilidades de derrotar a North Dakota St. (16) el 22 de marzo de 2019.
Pruebe cambiando el filtro school_ncaa anterior a fin de predecir los enfrentamientos en su ronda. Escriba cuál es la certeza del modelo y disfrute de los partidos.
¡Felicitaciones!
Lo logró. Usó el aprendizaje automático para predecir los equipos ganadores del torneo de básquetbol masculino de la NCAA.


Finalice su Quest
Este lab de autoaprendizaje forma parte de las Quests NCAA® March Madness®: Bracketology with Google Cloud y BigQuery for Machine Learning de Qwiklabs. Una Quest es una serie de labs relacionados que forman una ruta de aprendizaje. Si completa esta Quest, obtendrá una insignia como reconocimiento por su logro. Puede hacer públicas sus insignias y agregar vínculos a ellas en su currículum en línea o en sus cuentas de redes sociales. Si realizó este lab, inscríbase en alguna de las Quests y obtenga un crédito inmediato de finalización. [Consulte otras Quests de Qwiklabs disponibles](http://google.qwiklabs.com/catalog).
Realice su próximo lab
Esperamos que haya disfrutado de todo lo que aprendió sobre la exploración de macrodatos y la rapidez con la que puede crear modelos de aprendizaje automático dentro de BigQuery. Luego, pruebe lo siguiente:
Próximos pasos/Más información
- ¿Quiere obtener más información sobre las métricas y el análisis de básquetbol? Consulte el análisis adicional del equipo encargado de las predicciones y los anuncios del torneo de la NCAA de Google Cloud
- Descubra lo que puede hacer con el ML en Cómo usar el aprendizaje automático en Compute Engine para generar recomendaciones de productos
- Quest Data Science
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 8 de octubre de 2020
Prueba más reciente del lab: 8 de octubre de 2020
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.