チェックポイント
Run Cloud Dataprep jobs to BigQuery
/ 100
Cloud Dataprep でデータ変換パイプラインを作成する
このラボは Google のパートナーである Alteryx と共同開発されました。アカウント プロフィールでサービスの最新情報、お知らせ、特典の受け取りをご希望になった場合、お客様の個人情報が本ラボのスポンサーである Alteryx と共有される場合があります。
GSP430

概要
Cloud Dataprep by Alteryx は、分析を目的として、データの視覚的な探索、クリーニング、準備を行うためのインテリジェント データ サービスで、構造化データと非構造化データの両方に対応しています。このラボでは、Cloud Dataprep の UI を実際に使用して、結果が BigQuery に出力されるデータ変換パイプラインを作成します。
ここで使用するのは、Google Merchandise Store に関する数百万件の Google アナリティクス セッション レコードで構成される ecommerce データセットで、すでに BigQuery に読み込まれています。このデータセットのコピーを使用して、フィールドや行からどのような分析情報が得られるのかを確認します。
目標
このラボでは、次のタスクの実行方法について学びます。
- BigQuery データセットを Cloud Dataprep に接続する。
- Cloud Dataprep でデータセットの品質を調べる。
- Cloud Dataprep でデータ変換パイプラインを作成する。
- BigQuery に出力される変換ジョブを実行する。
設定と要件
このラボを始める前に、Working with Cloud Dataprep on Google Cloud ラボを受講することをおすすめします。
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

タスク 1. Google Cloud Dataprep を開く
-
Cloud コンソールでナビゲーション メニューに移動し、[分析] 下の [Dataprep] を選択します。
-
Cloud Dataprep を使用するには、チェックボックスをオンにして Google Dataprep の利用規約に同意し、[同意する] をクリックします。
-
アカウント情報が Alteryx と共有されることを知らせるプロンプトが表示されたら、チェックボックスをオンにして [同意して続行] をクリックします。
-
[許可] をクリックして、Alteryx がプロジェクトにアクセスできるようにします。
-
Qwiklabs の認証情報を選択してログインし、[許可] をクリックします。
-
チェックボックスをオンにし、[同意する] をクリックして Alteryx の利用規約に同意します。
-
ストレージ バケットのデフォルトの場所を使用するように求められたら [Continue] をクリックします。
タスク 2. BigQuery データセットを作成する
このラボでは主に Cloud Dataprep を使用しますが、BigQuery も必要です。BigQuery は、パイプラインへのデータセット取り込み用のエンドポイント、およびパイプライン完了時の出力先として使用します。
-
Cloud コンソールで、ナビゲーション メニューから [BigQuery] を選択します。
-
[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスにはクイックスタート ガイドへのリンクと、UI の更新情報が表示されます。
-
[完了] をクリックします。
-
[エクスプローラ] ペインでプロジェクト名を選択します。
![[エクスプローラ] ペイン](https://cdn.qwiklabs.com/rA3k8hwOv8d%2BtFoMB0d96eFRvUuEEhkW%2BXKTg3mC8WA%3D)
- 左側のペインの [エクスプローラ] セクションで、プロジェクト ID の右側にある [アクションを表示] アイコン(
)をクリックし、[データセットを作成] をクリックします。
- [データセット ID] に「
ecommerce」と入力します。 - その他の値はデフォルトのままにします。
-
[データセットを作成] をクリックします。左側のペインのプロジェクトの下に、このデータセットが表示されます。
-
次の SQL クエリをコピーして、クエリエディタに貼り付けます。
-
[実行] をクリックします。このクエリは、一般公開されている ecommerce の生データセットの一部(1 日分のセッション データに相当する約 56,000 件のレコード)を
all_sessions_raw_dataprepという名前の新しいテーブルにコピーします。このテーブルは ecommerce データセットに追加されており、Cloud Dataprep を使用してデータの探索やクリーニングができるようになります。 -
ecommerceデータセットにこの新しいテーブルが存在することを確認します。
タスク 3. BigQuery データを Cloud Dataprep に接続する
このタスクでは、Cloud Dataprep を BigQuery データソースに接続します。Cloud Dataprep のページで次の操作を行います。
-
右隅にある [Create a flow] をクリックします。
-
[Untitled Flow] の名前を変更し、以下の詳細を指定します。
- [Flow Name] に「
Ecommerce Analytics Pipeline」と入力します。 - [Flow Description] に「
Revenue reporting table」と入力します。
-
[OK] をクリックします。
-
[
What's a flow?] というポップアップが表示された場合は、[Don't show me any helpers] を選択します。 -
Dataset ボックスで [Add] アイコンをクリックします。
![[Add] アイコンがハイライト表示されている](https://cdn.qwiklabs.com/k%2BTy2cx5xnl0DwdmQngGjEGU5ZU1mnb7vsm7PMkQJwE%3D)
-
[Add Datasets to Flow] ダイアログ ボックスで、[Import Datasets] を選択します。
-
左側のペインで [BigQuery] をクリックします。
-
ecommerce データセットが読み込まれたら、それをクリックします。
-
all_sessions_raw_dataprep テーブルの左側にある [
Create dataset] アイコン(+ 記号)をクリックします。 -
右下にある [Import & Add to Flow] をクリックします。
データソースが自動的に更新され、次のタスクに進む準備が整いました。
タスク 4. UI を使って ecommerce データセットのフィールドを探索する
このタスクでは、Cloud Dataprep で ecommerce データセットのサンプルを読み込んで探索します。
- [Recipe] アイコンをクリックし、[Edit Recipe] を選択します。
![[Recipe] アイコンと [Edit Recipe] ボタンがハイライト表示されている](https://cdn.qwiklabs.com/G3PDFXsoKjxJQTIpLgT%2BLYEO742qE8OqE%2BR3q2PLPyM%3D)
[Transformer] ビューにデータセットのサンプルが読み込まれます。この処理には数秒かかる場合があります。これで、データを探索するための準備が整いました。
次の質問に答えてください。
- このデータセットには列がいくつありますか。
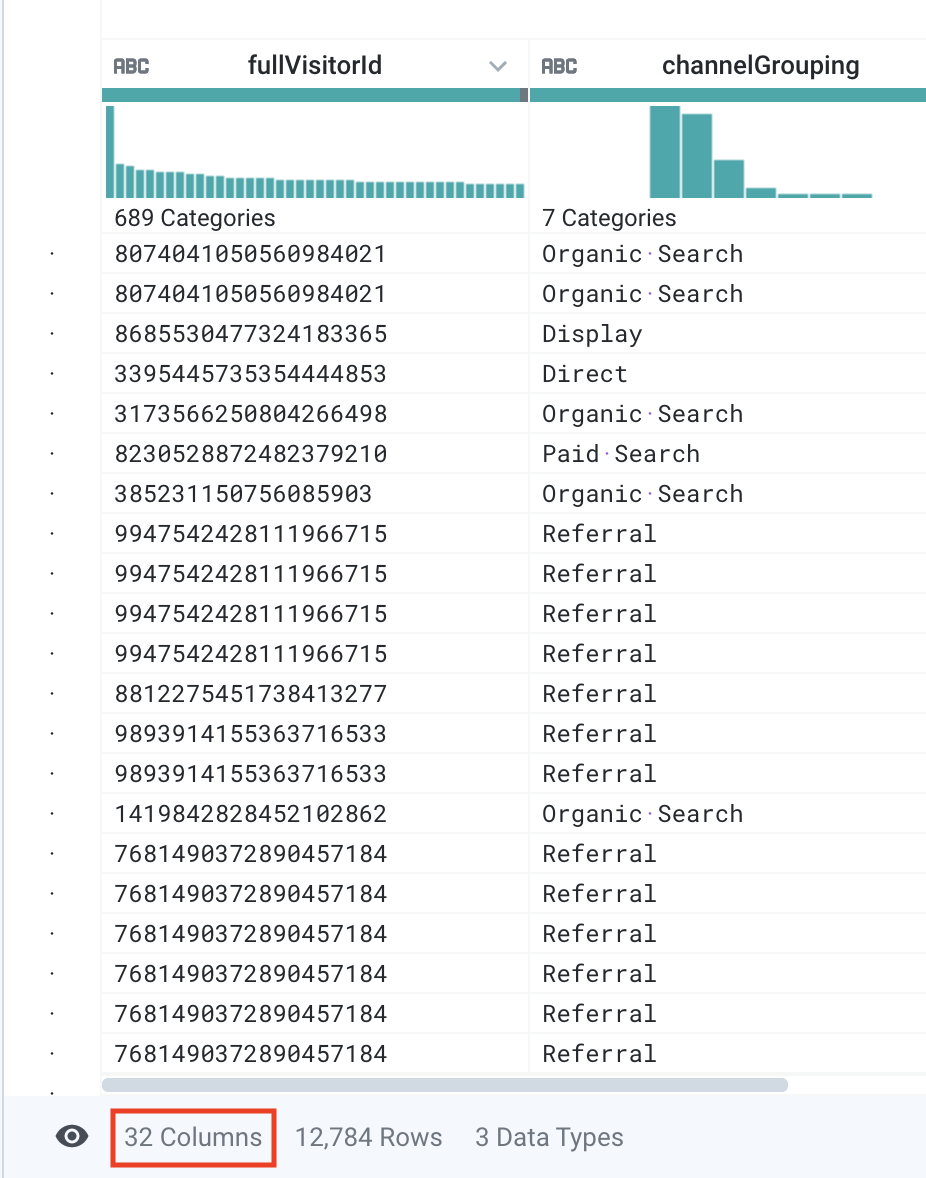
答え: 32 列。
- このサンプルには行がいくつ含まれていますか。
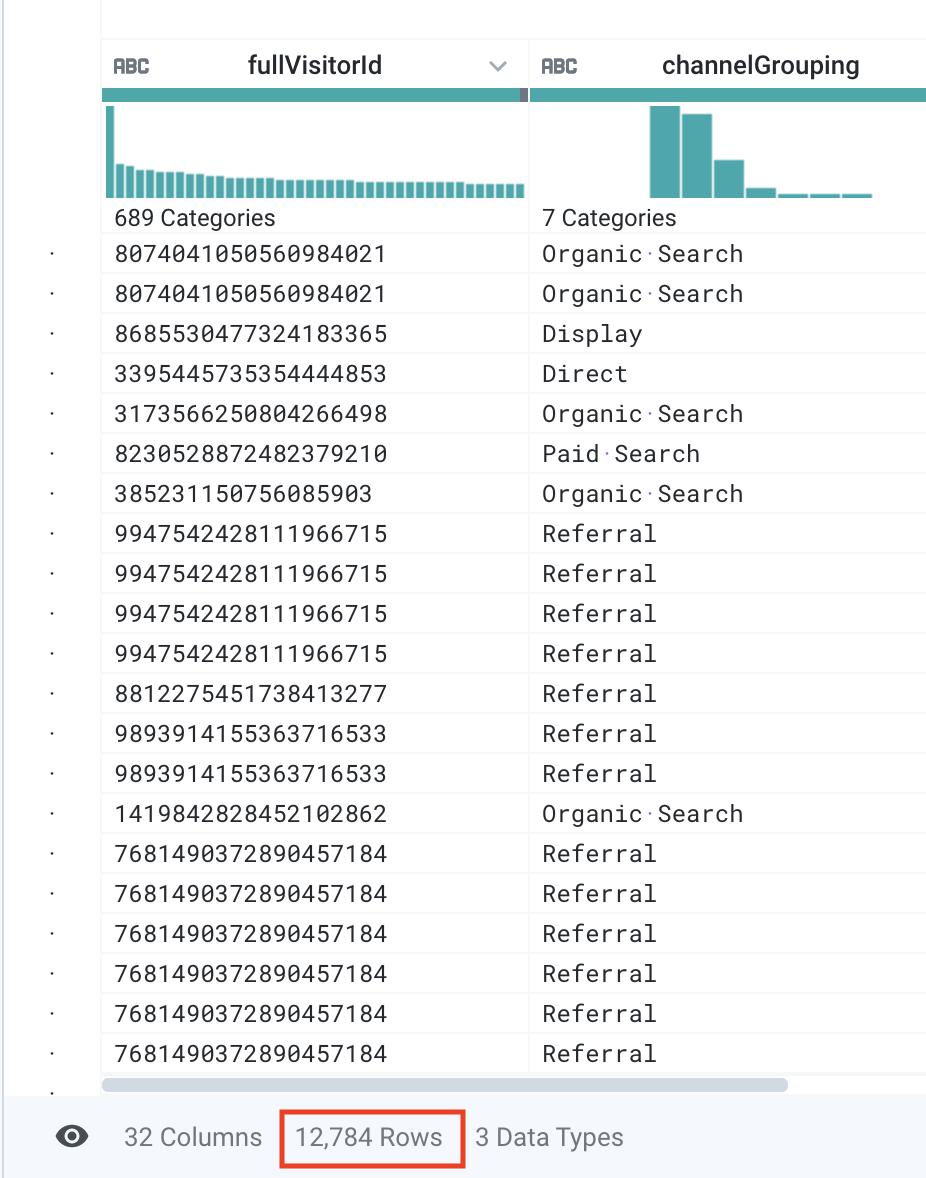
答え: 約 12,000 行。
-
channelGrouping列で最も頻繁に出現する値は何ですか。
channelGrouping 列のタイトルの下にあるヒストグラムにカーソルを合わせるとわかります。
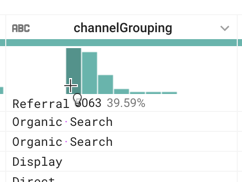
答え: Referral。Referral(参照元サイト)は通常、該当するコンテンツへのリンクを含む他のウェブサイトです。たとえば、この e コマースサイトの商品をレビューしてリンクを掲載している別のウェブサイトがこれに当たります。この場合、検索エンジンからのアクセスとは異なる集客チャネルと見なされます。
![[Find column] アイコン](https://cdn.qwiklabs.com/Ui5aE9D%2FnzHJzNjz1IX48nZPBtuIhbd8YNvv9JZ4r3M%3D) )をクリックします。[Find column] テキストフィールドで列名の入力を開始し、列名が表示されたらクリックします。グリッドが自動的にスクロールして、その列が画面に表示されます。
)をクリックします。[Find column] テキストフィールドで列名の入力を開始し、列名が表示されたらクリックします。グリッドが自動的にスクロールして、その列が画面に表示されます。- セッション数が多い接続元の上位 3 か国はどこですか。
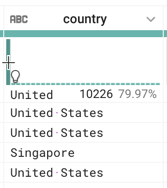
答え: 米国、インド、英国
- totalTransactionRevenue 列の下にある灰色のバーは何を表していますか。
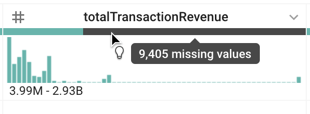
答え: totalTransactionRevenue フィールドの値がないデータ。ここから、このサンプルの多くのセッションで収益が得られなかったことがわかります。後ほどこれらの値を除外して、収益に関連する顧客トランザクションのみが最終的なテーブルに含まれるようにします。
- このデータサンプルの
timeOnSite(秒)、pageviews、sessionQualityDimの最大値はそれぞれいくつですか(ヒント:timeOnSite列の右側にあるメニューを開き(をクリック)、[Column Details] メニューを選択します)。
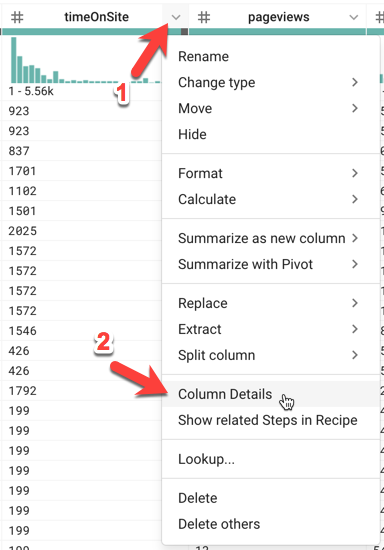
![[timeOnSite Overview] タブのページ](https://cdn.qwiklabs.com/Hp2p2%2FjlETLLD0Uz6Nurf8HhWCY3BhUlU4t7n357ymM%3D)
詳細ウィンドウを閉じるには、右上にある [Close Column Details](X)ボタンをクリックします。同じ手順で pageviews 列と sessionQualityDim 列の詳細も確認します。
![[閉じる] ボタン](https://cdn.qwiklabs.com/pnBT9jpB%2F%2F1fF5UgnwKlR960bjuSjmPxRGU9oWTkT8o%3D)
答え:
- サイト滞在時間(timeOnSite)の最大値: 5,561 秒(92 分)
- ページビュー(pageviews)の最大値: 155 ページ
- 「セッションの品質」ディメンション(sessionQualityDim)の最大値: 97
timeOnSite のようなフィールドはセッションにつき 1 回しかカウントされないことを理解する必要があります。訪問者とセッションのデータの一意性については後のラボで学びます。
-
sessionQualityDimの値は均等に分布していますか(この列のヒストグラムを確認します)。
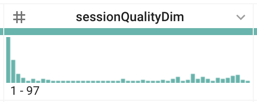
答え: いいえ。低い値(低品質のセッション)に偏っていますが、これは予想どおりです。
- このデータセットの date の範囲はいつですか(ヒント: date フィールドを確認します)。
答え: 2017 年 8 月 1 日(1 日のデータ)
-
productSKU列の下に赤いバーが表示されることがあります。これは何を表していますか。
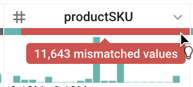
答え: 赤いバーは不適切な値を示しています。Cloud Dataprep では、データのサンプリング時に各列の型が自動的に識別されます。productSKU 列に赤いバーが表示されていない場合は、この列の型が正しく(String 型として)識別されたことになります。赤いバーが表示されている場合は、サンプルで数値が多く見つかったために Integer 型として(誤って)識別されたことになります。ただし、整数以外の値も検出されたために、それらが不適切な値として報告されています。実際、productSKU は整数であるとは限りません(たとえば、「GGOEGOCD078399」が正しい値である場合もあります)。そのため、この場合は Cloud Dataprep が列の型を誤って識別したことになります(Integer ではなく String でなければなりません)。この修正は後ほどこのラボで行います。
- 特に人気の高い商品は何ですか(
v2ProductName列を確認します)。
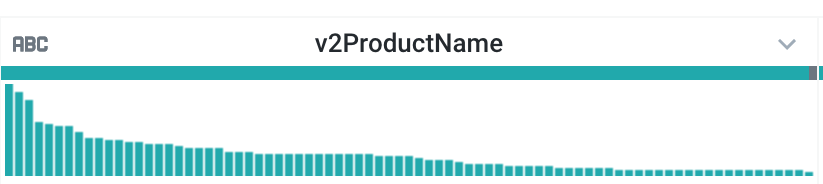
正解: Google Nest 製品
- 特に人気の高い商品カテゴリは何ですか(
v2ProductCategory列を確認します)。いくつか例を挙げてください。
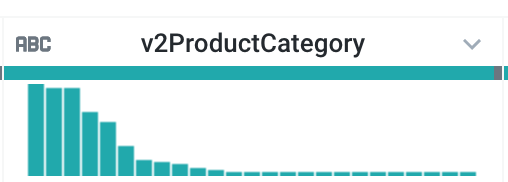
答え:
最も人気の高い商品カテゴリは次のとおりです。
-
Nest
-
Bags
-
(not set)(カテゴリが関連付けられていないセッションを示しています)
-
次の説明は正しいですか。
productVariantの最頻値はCOLORである。
答え: 正しくありません。最頻値は (not set) で、ほとんどの商品(80% 以上)にはバリエーションがありません。
- type 列には値が 2 つあります。それらは何ですか。
正解: PAGE と EVENT
ウェブサイトを閲覧するユーザーのインタラクションにはさまざまなタイプがあります。たとえば、ページを表示したときにセッション データが記録される PAGE や、「商品のクリック」のような特殊なイベントに対応する EVENT などがこれに当たります。複数のヒットタイプが同時にトリガーされる可能性があるため、二重にカウントされるのを防ぐためにタイプでフィルタするのが一般的です。これについては後の分析ラボで詳しく学びます。
-
productQuantityの最大値はいくつですか。
答え: 100(この答えは異なる場合があります)
productQuantity は、カートに追加された商品の個数を示します。値が 100 の場合、1 つの商品が 100 個追加されたことになります。
- トランザクションで
currencyCodeの大半を占めている値は何ですか。
答え: USD(米ドル)
-
itemQuantityまたはitemRevenueに有効な値はありますか。
答え: いいえ。すべての値が NULL 値(欠損値)です。
-
transactionId列で値が有効なのは全体の何パーセントですか。この比率はecommerceデータセットの何を表していますか。
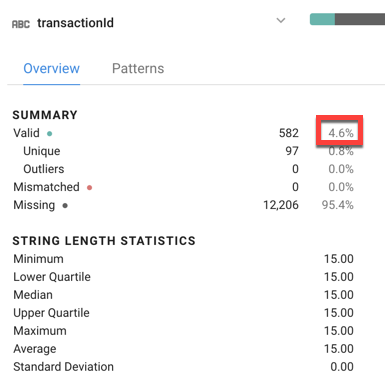
- 答え: 有効な値を持つトランザクション ID は約 4.6% です。この比率は、このウェブサイトの平均コンバージョン率を表しています(訪問者の 4.6% が購入)。
-
eCommerceAction_typeには値がいくつありますか。また、最頻値は何ですか。

答え: このサンプルで見つかった値は 7 個です。最頻値はゼロ(0)で、タイプが不明であることを表しています。このウェブサイトのウェブ セッションは大半が閲覧のみで、e コマース アクションは行われないため、この結果は理にかなっています。
-
eCommerceAction_type = 6 は何を表していますか(
スキーマを使用して答えてください)。
eCommerceAction を検索してマッピングの説明を読みます。
答え: 6 は「Completed purchase」(購入完了)にマッピングされています。このラボで後ほど、このマッピングをデータ パイプラインの一部として取り込みます。

タスク 5. データをクリーニングする
このタスクでは、データをクリーニングするために、使用しない列の削除、重複行の排除、計算フィールドの作成、不要な行の除外を行います。
productSKU 列のデータ型を変換する
-
productSKU 列のデータ型が string になるようにします。productSKU 列の右側にあるメニューを開き(
![productSKU > [Change type] > [String]](https://cdn.qwiklabs.com/h9XRQZfWpeWFemjzgS90OJIJyC68beZ0TXHPNun6nqM%3D)
- [Recipe] アイコンをクリックして、このデータ変換パイプラインの最初のステップが作成されたことを確認します。
![[Recipe] アイコン](https://cdn.qwiklabs.com/QqCACDwXBSL6Va99bq%2FsnytTzLgd3%2BuHbPqxbDsTr68%3D)
使用しない列を削除する
前述のように、itemQuantity 列と itemRevenue 列を削除します。これらの列には NULL 値しか含まれていないため、このラボでは必要ありません。
- itemQuantity 列のメニューを開いて [Delete] をクリックします。
![[Delete] メニュー オプションがハイライト表示されている itemQuantity 列](https://cdn.qwiklabs.com/D7Pv7GOsFWtLIVQK6TwOINOxqNTdx17IWNlhDO94XL0%3D)
- 同じ手順で itemRevenue 列も削除します。
重複行を排除する
ソース データセットに重複したセッション値が含まれている可能性があるという報告を受けたため、重複排除の手順に沿ってそれらを削除します。
- ツールバーの [Filter rows] アイコンをクリックし、[Remove duplicate rows] をクリックします。
![[Remove duplicate] オプションがハイライト表示されている [Filter rows] プルダウン メニュー](https://cdn.qwiklabs.com/8M2UYHCAl7encUqMsXJih7FZbmK4TwaRzceV0LMVgaY%3D)
-
右側のパネルで [Add] をクリックします。
-
これまでに作成したレシピを確認します。次のようになっているはずです。
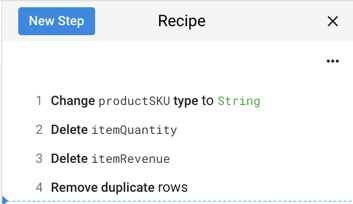
収益のないセッションを除外する
このウェブサイトで少なくとも 1 つの商品を購入したすべてのユーザー セッションを含むテーブルを作成するように依頼されました。収益が NULL のユーザー セッションを除外します。
- totalTransactionRevenue 列の下で、灰色の Missing values バーをクリックします。totalTransactionRevenue の値がないすべての行が赤でハイライト表示されます。
- [Suggestions] パネルの [Delete rows] で [Add] をクリックします。
![[Suggestions] パネル](https://cdn.qwiklabs.com/AtSqaRx%2Bungs9s7v9ZYAWfapqjbHItEto9kmzDb6oi0%3D)
これにより、データセットがフィルタされて、収益のある(totalTransactionRevenue が NULL ではない)トランザクションのみが表示されるようになります。
セッションをページビューでフィルタする
このデータセットには、さまざまなタイプのセッションが含まれています(例: PAGE - ページビュー、EVENT - 「商品カテゴリの表示」、「カートへの追加」などのトリガーされたイベント)。セッションのページビューが二重にカウントされないように、フィルタを追加して、ページビュー関連のヒットのみが含まれるようにします。
-
type 列の下にあるヒストグラムで PAGE のバーをクリックします。type が PAGE のすべての行が緑色でハイライト表示されます。
-
[Suggestions] パネルの [Keep rows] で [Add] をクリックします。
タスク 6. データのエンリッチメントを行う
スキーマのドキュメントで visitId を検索してその説明を読み、この値がすべてのユーザー セッションに対して一意なのか、そのユーザーに対してのみ一意なのかを確認します。
-
visitId: このセッションの識別子。通常はutmbCookie として保存される値の一部で、そのユーザーに対してのみ一意です。完全に一意の ID の場合は、「fullVisitorId」と「visitId」を併用してください。
この説明から、visitId がすべてのユーザーに対して一意ではないことがわかります。そのため、一意の ID を作成する必要があります。
一意のセッション ID に対応する新しい列を作成する
すでに確認したように、このデータセットには一意のユーザー セッションを表す単一の列がありません。fullVisitorId フィールドと visitId フィールドを連結して各セッションの一意の ID を作成します。
- ツールバーの [Merge columns] アイコンをクリックします。
![[Merge columns] アイコン](https://cdn.qwiklabs.com/4p8pt0WP6h%2BMERLwCgIWDp%2B5WDIwN8XRyo45nbcw07w%3D)
-
[Columns] で、[
fullVisitorId] と [visitId] を選択します。 -
[Separator] にハイフン(「
-」)を 1 つ入力します。 -
[New column name] に「
unique_session_id」と入力します。
![[Merge columns] パネル](https://cdn.qwiklabs.com/Xc1sUxfFNb48M%2FH1G61NgHc8kaSJidHOYyg0yv6WJeg%3D)
- [Add] をクリックします。
fullVisitorId と visitId を組み合わせた unique_session_id が新たに作成されます。このラボで後ほど、このデータセットの各行が一意のセッション単位なのか(ユーザー セッションごとに 1 行)、それより細かい単位のデータなのかを調べます。
e コマース アクション タイプの case ステートメントを作成する
すでに確認したとおり、eCommerceAction_type 列の値は整数で、そのセッションで実行された実際の e コマース アクションにマッピングされています。たとえば、3 は「カートに追加」、5 は「決済」を表します。このマッピングはエンドユーザーにとってわかりにくいため、値の名前を取り込む計算フィールドを作成します。
- ツールバーの [Conditions] をクリックし、[Case on single column] をクリックします。
![[Case on single column] オプションがハイライト表示されている [Conditions] プルダウン メニュー](https://cdn.qwiklabs.com/CuaxX3SVElvxsAij2wJThUdkT%2BB%2B2MemzepIijLrQzU%3D)
-
[Column to evaluate] で [
eCommerceAction_type] を指定します。 -
[Cases (1)] の横にある [Add] を 8 回クリックして、かっこ内の数が 9 になるようにします。
![[Conditions] セクション](https://cdn.qwiklabs.com/mzgyn4an4E2T1qFfBiBxlRuf0qJpCkLRIOfBlbVpSX0%3D)
- 各 Case に対して次のマッピング値を指定します(単一引用符も含めます)。
|
Comparison |
New value |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![評価対象の列「eCommerceAction_type」の評価のプレビューが表示されている [Conditions] パネル](https://cdn.qwiklabs.com/%2FqJ2lGNSkW2G7G6K%2FSUkIRqHrg28kLYruYht1%2FzvWMg%3D)
-
[New column name] に「
eCommerceAction_label」と入力します。他のフィールドはデフォルト値のままにします。 -
[Add] をクリックします。
totalTransactionRevenue 列の値を調整する
スキーマで説明されているように、totalTransactionRevenue 列には、アナリティクスに渡される値に 10 の 6 乗を掛けた数値が含まれています(例:2.40 は 2400000 になります)。ここでは、この列の値を 10 の 6 乗で割って元の値を取得します。
-
totalTransactionRevenue 列の右側にあるメニューを開き(
![[Custom formula] がハイライト表示されている](https://cdn.qwiklabs.com/LAs4nQx3xR5AOiXmVbCnX1amcUbzsBn%2FiQizgdfJ%2F%2B8%3D)
- [Formula] に「
DIVIDE(totalTransactionRevenue,1000000)」と入力し、[New column name] に「totalTransactionRevenue1」と入力します。変換のプレビューが表示されます。
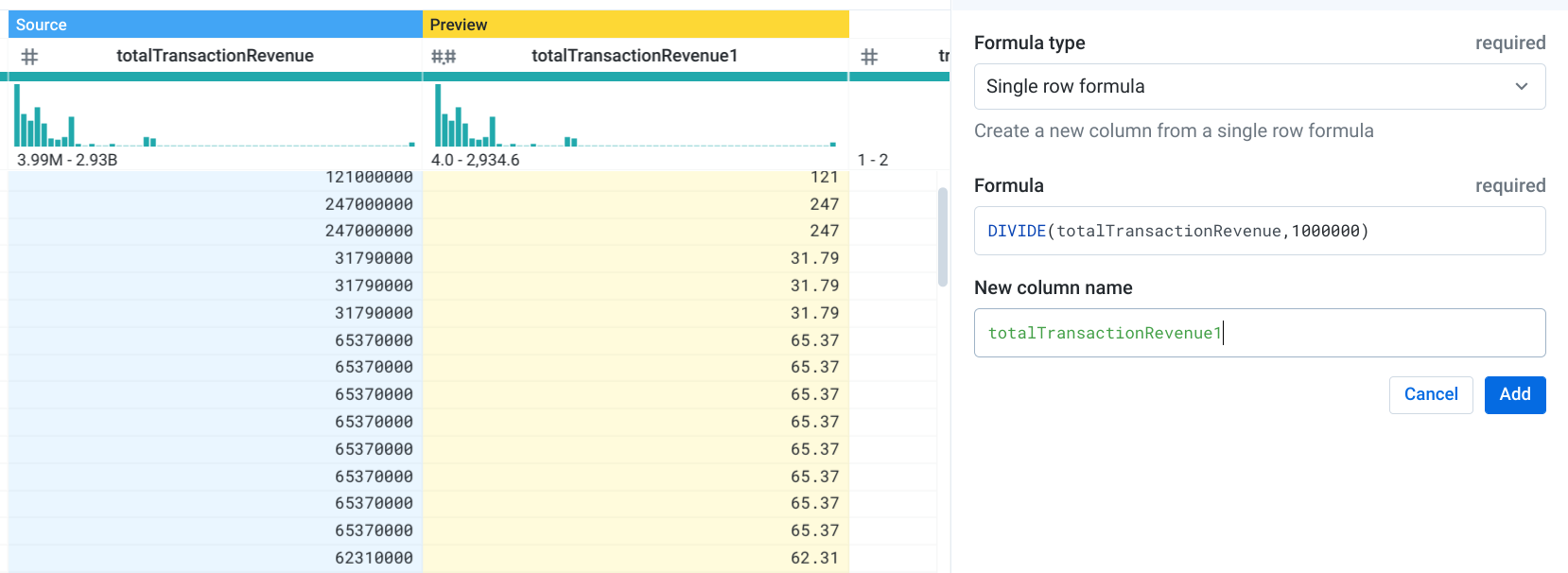
- [Add] をクリックします。
totalTransactionRevenue1 列の下に赤いバーが表示されることがあります。totalTransactionRevenue1 列の右側にあるメニューを開き( をクリック)、[Change type] > [Decimal] の順にクリックします。- レシピのすべてのステップを確認します。
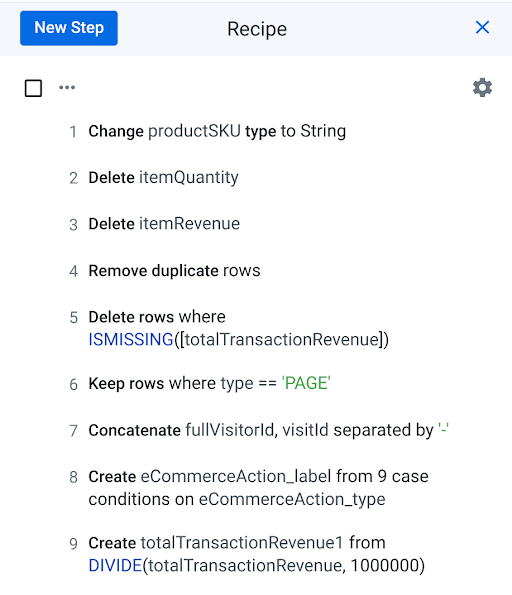
- [Run] をクリックできるようになります。
タスク 7. Cloud Dataprep ジョブを BigQuery に対して実行する
-
[Run Job] ページで、[Running Environment] に [Dataflow + BigQuery] を選択します。
-
[Publishing Actions] で、[Create-CSV] の右にある [Edit] をクリックします。
-
次のページで、左側のメニューから [BigQuery] を選択します。
-
[ecommerce] データセットを選択します。
-
右側のパネルで [Create a New Table] をクリックします。
-
テーブルに [revenue_reporting] という名前を付けます。
-
[Drop the Table every run] を選択します。
-
[Update] をクリックします。
-
[RUN] をクリックします。
Cloud Dataprep ジョブが完了したら、BigQuery のページを更新して、出力テーブルの revenue_reporting が存在することを確認します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
お疲れさまでした
ここでは Cloud Dataprep を使用して、ecommerce データセットを探索し、データ変換パイプラインを作成しました。
クエストを完了する
このセルフペース ラボは、「Data Engineering」クエストの一部です。クエストとは学習プログラムを構成する一連のラボのことで、完了すると成果が認められてバッジが贈られます。バッジは公開して、オンライン レジュメやソーシャル メディア アカウントにリンクできます。こちらのクエストに登録すると、すぐにクレジットを受け取ることができます。受講可能な全クエストについては、Google Cloud Skills Boost カタログをご覧ください。
次のラボを受講する
Google Cloud での Dataflow と BigQuery を使用した ETL 処理に進んでクエストを続けるか、以下のおすすめのラボをご確認ください。
次のステップと詳細情報
-
Google Cloud Marketplace の Alteryx
-
すでに Google アナリティクス アカウントをお持ちで、BigQuery で独自のデータセットに対してクエリを実行されたい場合は、こちらのエクスポート ガイドに沿って行ってください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 9 月 20 日
ラボの最終テスト日: 2023 年 9 月 20 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。